
Idea: Variable column names and de-pivoting
-
I've got the following challenge:
Input data is stored in a csv file, it has a daily changing number of columns (say 20-25), 10 of which have fixed names while the rest are named with dates. I want to de-pivot only the date-named columns.
The problem is that the number and names of the date columns change daily. Hence a simple de-pivot operation doesn't work once the data has been changed. Ideally I want a de-pivot option where it de-pivots all the columns apart from the selected ones.
Is it possible to achieve such de-pivoting in Omniscope some way? And if not would an option 'de-pivot everything apart from selected columns' be possible to include into de-pivot operation?
P.S. I tried every combination of operations I thought might lead me somewhere, and almost got the result, but in Summarise operation selecting "All fields" doesn't keep all the fields selected after the field names changed, the way that most other operations work. Is that intended? -
12 Comments
-
YGulla - Any de-pivot operation potentially introduces new, unpredictable column/field names into a data set, and there are some currently-unsolved problems associated with this. In addition to to the feature your request, there is also probably a need to be able to define a predictable re-naming convention for the new fields/columns created by the de-pivot, e.g. [Last Period] or [Latest Data].
I have reclassified this as an Idea to draw out a fuller specification of the issues commonly encountered with repeated de-pivots of accrescent (increasing, expanding, enriching over time) data. -
Hmm I can't actually see the problem.
De-pivot creates only 2 new fields [Pivot series] and [Pivot values] redardless of the number of de-pivoted columns and those names are already defined by the user.
In fact Omniscope already has a de-pivot that handles variable number of columns - it is sufficient to select 'All' in the de-pivot window and it will de-pivot all fields even if the number of fields changes from run to run.
However if only a subset of fields is selected the new fields will appear unticked. I don't see a conceptual problem with making them appear ticked once some new option is selected.
(I'll post some screenshots to illustrate my words when I have a spare moment) -
I finally had some time to take some screenshots.
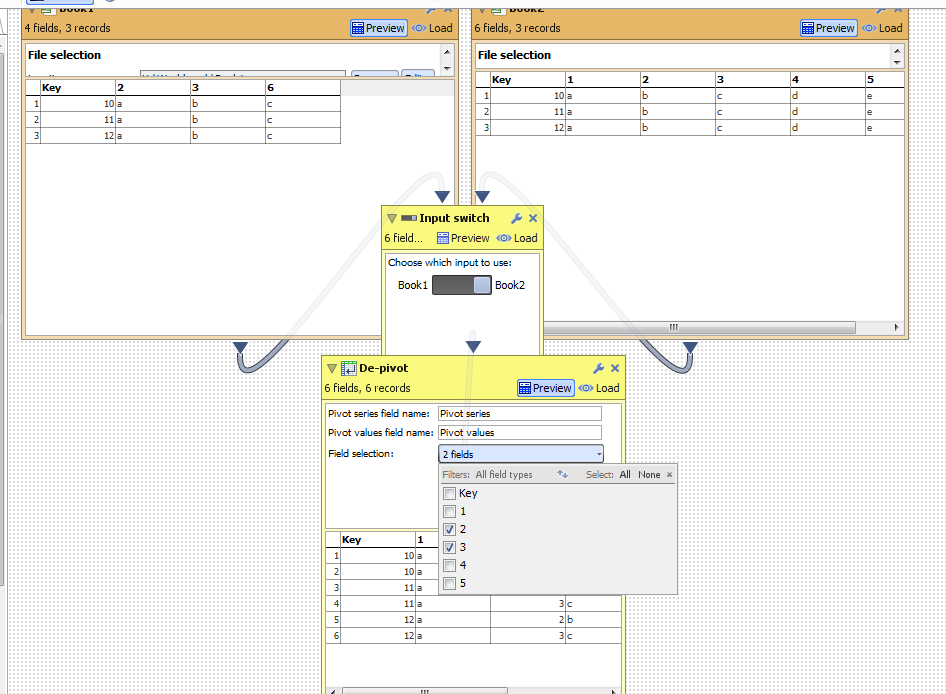
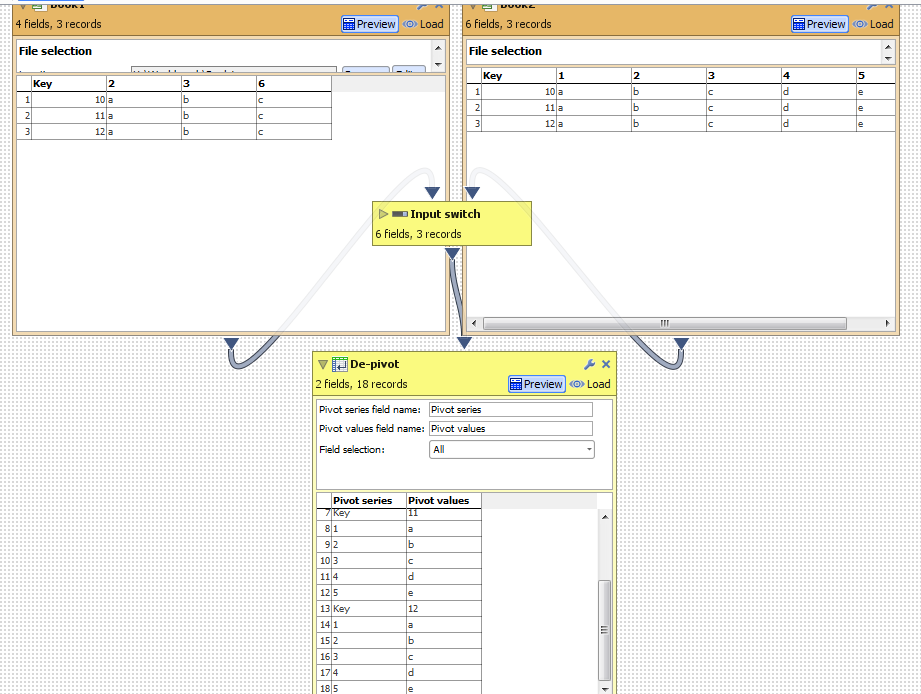
Here's what we have now if we select a few fields to depivot: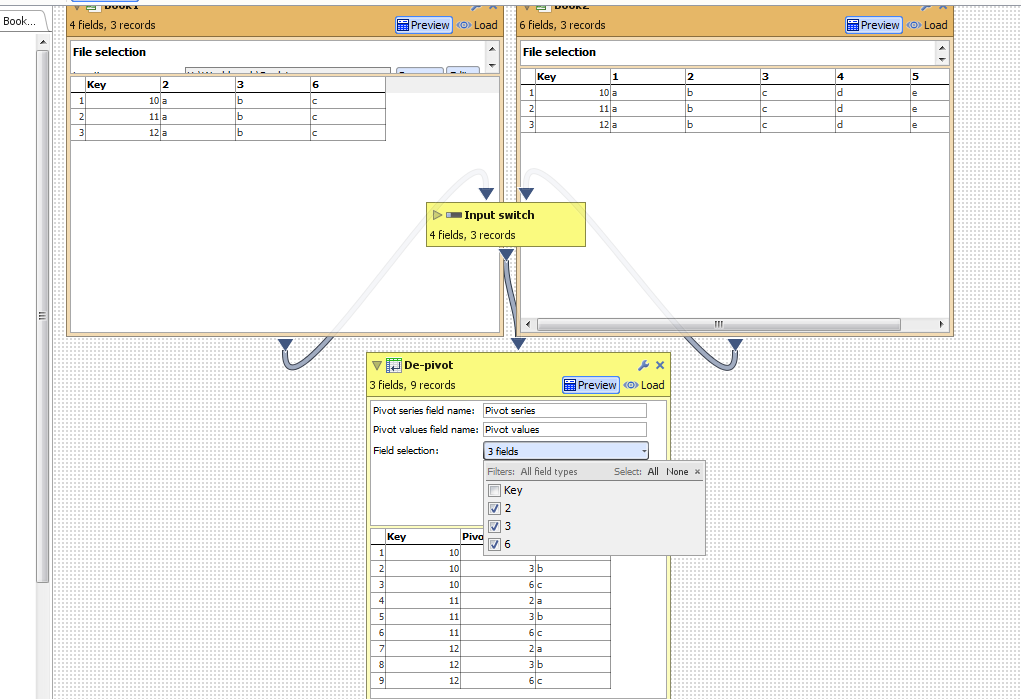
Then if the data changes according to my scenario (simulated by switching the input) I get the following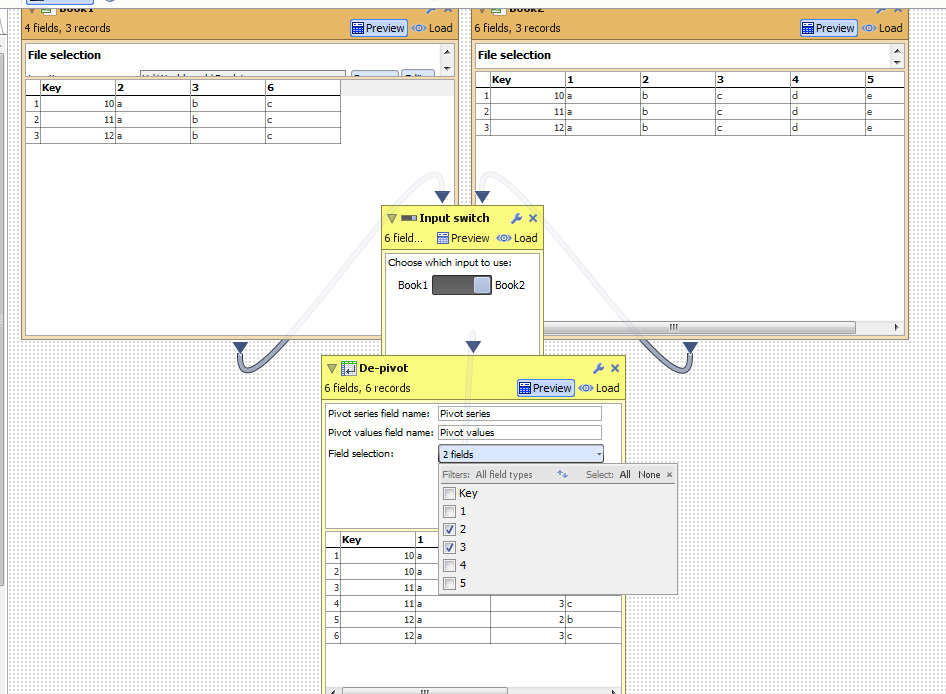
Whereas I want an option to set Omniscope to automatically select everything apart from unselected columns (i.e. 1-5 but not Key). And as far as I can see this should not be a problem as the functionality for such dynamic selection is already in Omniscope. If I choose "All" I get the desired result after the same change of input data: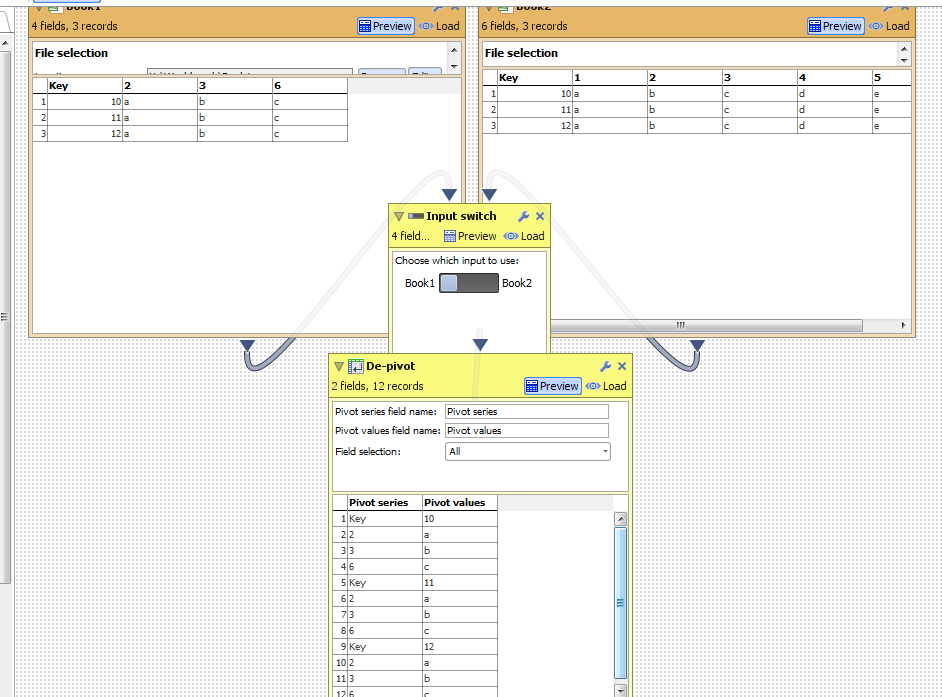
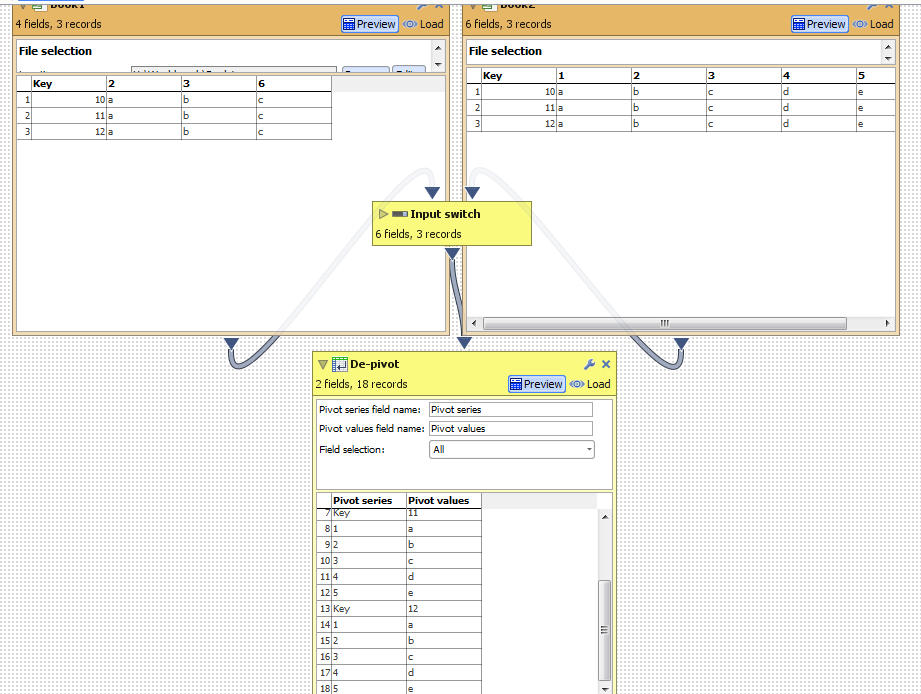
Notice how it depivoted all columns Key and 1-5 rather than just those that were present in data 1 (Key, 2 and 3)
YuriAttachmentsSelect Data1.png 54K Select Data2.png 53K All Data1.png 52K All Data2.png 48K 
De-pivot.iok 8K Book1.csv 41B Book2.csv 57B -
Makes sense. You need this so that your incoming data can change over time, with new fields coming and going, while always excluding "Key".
Currently the field picker has two states:
- "All": all fields are selected, regardless of how your data changes
- "3 fields selected": 3 fields are selected. If new fields appear, they will not be selected by default.
You want this:
- "1 field deselected": 1 field has been deselected. If new fields appear, they will be selected by default.
A simple option under (or in) the picker would solve this:
"Include new fields by default: [tick]"
or
"Default state for new fields: selected / deselected"
or
"Select fields by: inclusion / exclusion".
There might also be other places in DataManager which benefit from a standard option like this built into the field picker itself.
I have moved this into the Alpha Partner only area, and have made you an Alpha Partner so you can still see it. -
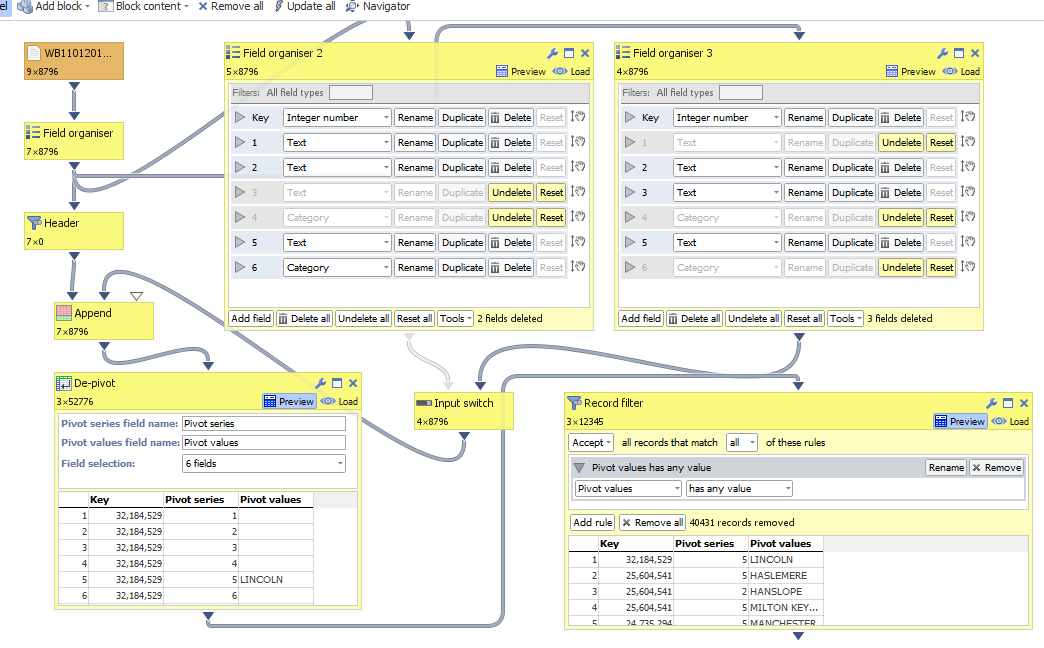
This would be very useful for us - lots of data from clients arrives in a 'pivoted' form and we need to depivot before processing... but the current insistence on naming the "moving" fields (rather than Steve's suggestion of naming the "static" fields) prevents automated use.
+1 from me for naming the "static" fields and ensuring ALL others are depivoted... but got for one of the more flexible options if you can!Atheon Analytics Ltd
w: www.atheonanalytics.com
e: guy.cuthbert@atheon.co.uk
t: +44 8444 145501
m: +44 7973 550528
s: guycuthbert -
Another idea is to allow you to pick the set of fields using some kind of rule, a little like you can in the "Field Filter" operation. If this was extended to support regular expressions, you'd be able to specify "matches regex
\d+" to match any field name such as "2012". -
Just a random and very late workaround, if you append a header only file with the full number of fields plus your regular changing data files, then it will always have the same defined headers.
Then when you de-pivot the data using a different input data, it will always have those same fields, so the options shouldn't change. You might need to insert a record filter to remove any empty rows generated when you de-pivot.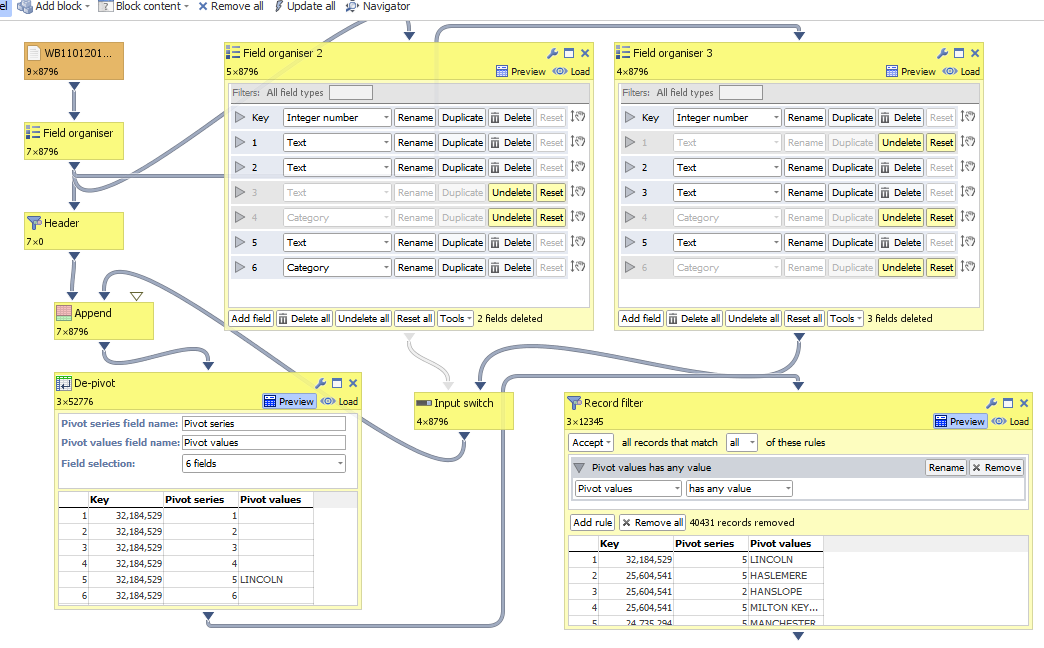 Attachments
AttachmentsdpCapture.PNG 91K -
but that only works if my field names don't change. If I have dates in the headers which would change week on week the De-Pivot would only pick up Dates that it already recognizes. So to get yours to work I would have to generate a header file with all the date that could exist for my date range (which could be 365 or more headers)
-
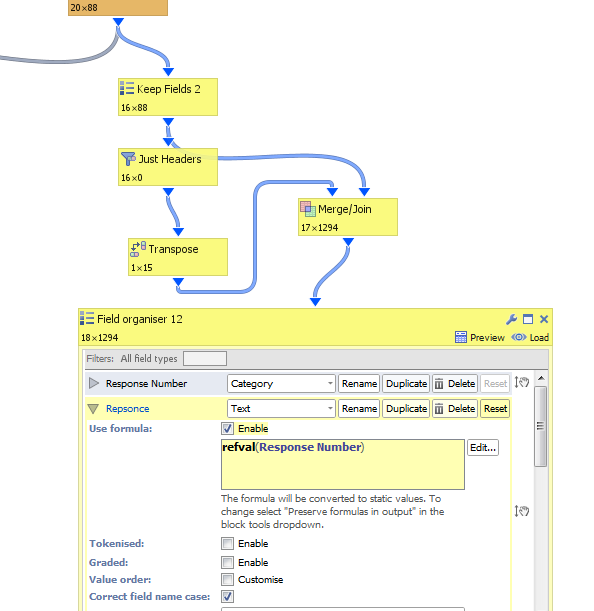
What Might work is if you do something similar but have headers transposed (with each top row as being the ones you want to keep), then merge with the data by Record number >= allow many to many. and then use refval formula to get the data you want.
My example is only with 1 header I want to keep, but it might work with with more headers you want to keep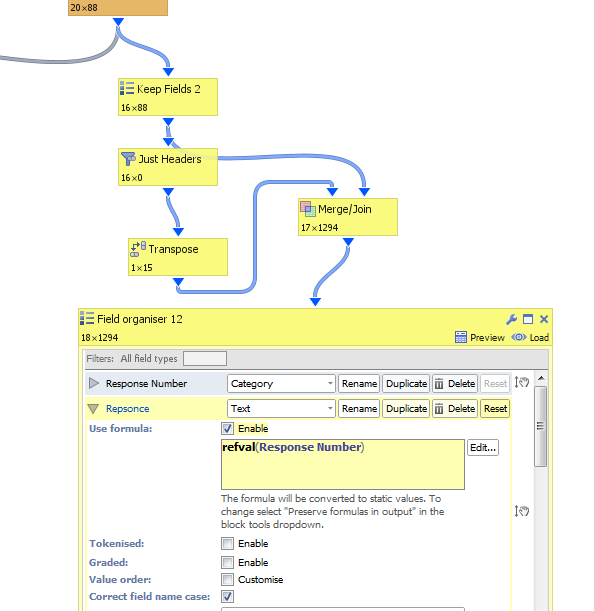 Attachments
AttachmentsDePivot altenative.PNG 35K -
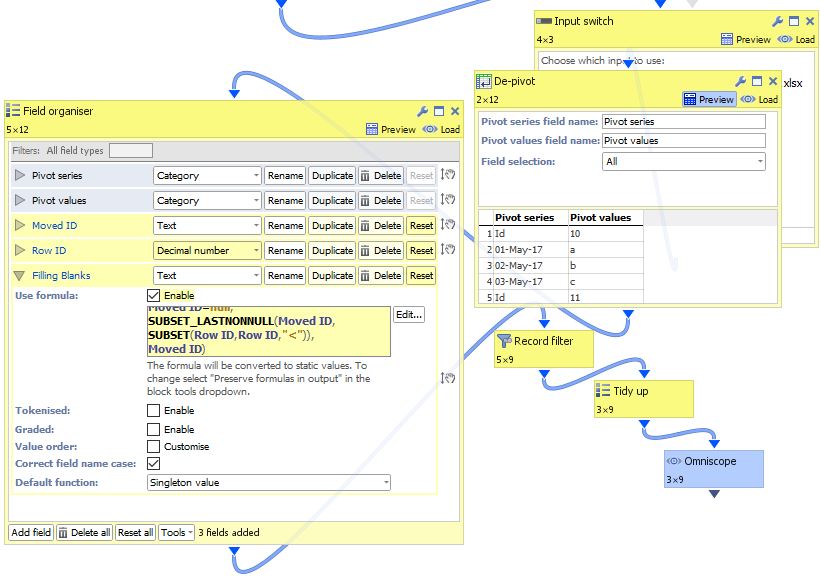
Transpose is too mechanical. Just de-pivot the whole dataset, then add few little formula helpers.
Moved ID=IF(
[Pivot series]="Id",
[Pivot values],
null)
Row ID = CURRENTROW
IF(
[Moved ID]=null,
SUBSET_LASTNONNULL([Moved ID], SUBSET([Row ID],[Row ID],"<")),
[Moved ID])
Works on dataset of any width - demo attached.
For the scenario where you have several fields that should stay 'as is', use a field filter above, then split the dataset (prior to de-pivot) into two, where both sets will preserve ID on which you can merge later.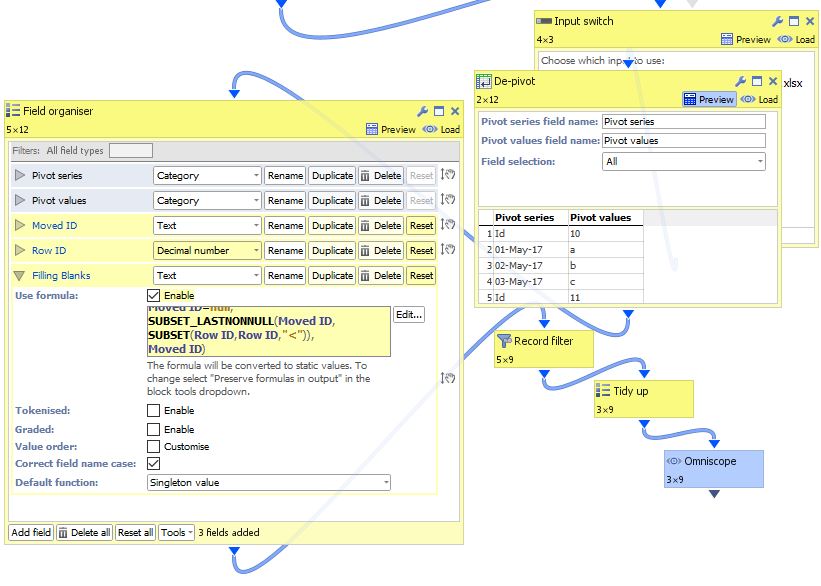 Attachments
Attachmentsorientation.JPG 83K ChangingDataOrientation.iok 10K





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Welcome!
It looks like you're new here. If you want to get involved, click one of these buttons!
Categories
- All Discussions2,595
- General680
- Blog126
- Support1,177
- Ideas527
- Demos11
- Power tips72
- 3.0 preview2
Tagged
To send files privately to Visokio email support@visokio.com the files together with a brief description of the problem.