
Enhanced Merge/Join Options
-
Are there any plans to enhance merge/join functionality to something similar to that of SQL?
More specifically - options that exceed value matching (ex: value comparison with static values or value comparisons between two tables that are not direct matches).
I spend a *lot* of horsepower trying to resolve the above and it typically ends with me appending the second table to the first, then creating a column which uses an unique_list / intersection / series of subsets.
Example:
Table 1
Employee Name | Extension| Job Role | Start Date | End Date
John Wilson | 1| agent | 1-may-2010 | 1-jan-2011
Jacob Harvell | 2| agent | 1-dec-2010 | 1-dec-2011
John Wilson | 1 | manager | 1-jan-2011 | 1-dec-2011
Billy Bones | 2 | agent | 1-may-2010 | 1-dec-2010
Table 2
Reported Date | ntlogin | handle time
1-Feb-2011 | 1| 120
1-Feb-2011 | 2| 7
If I only want to import handle times of agent data and bind their names I would need join conditions similar to
Tbl_1.ntlogin = Tbl_2.ntlogin AND Tbl_1.Job_Role = 'agent' AND Tbl_1.Start_Date <= Tbl_2.Reported_Date AND Tbl_1.End_Date > Tbl_2.Reported_Date
This is one example of many that I run into.
Currently, with only a match value join,I have to append the data and do the above by creating a column and performing a unique list / intersection / subsets to get the Employee name populated and then filter those that null.
Thanks,
-John -
7 Comments
-
Hi,
Could you achieve this in DataManager by using a record filter operation? We can use the record filter to select only agents. Please see the attached screenshot.Attachments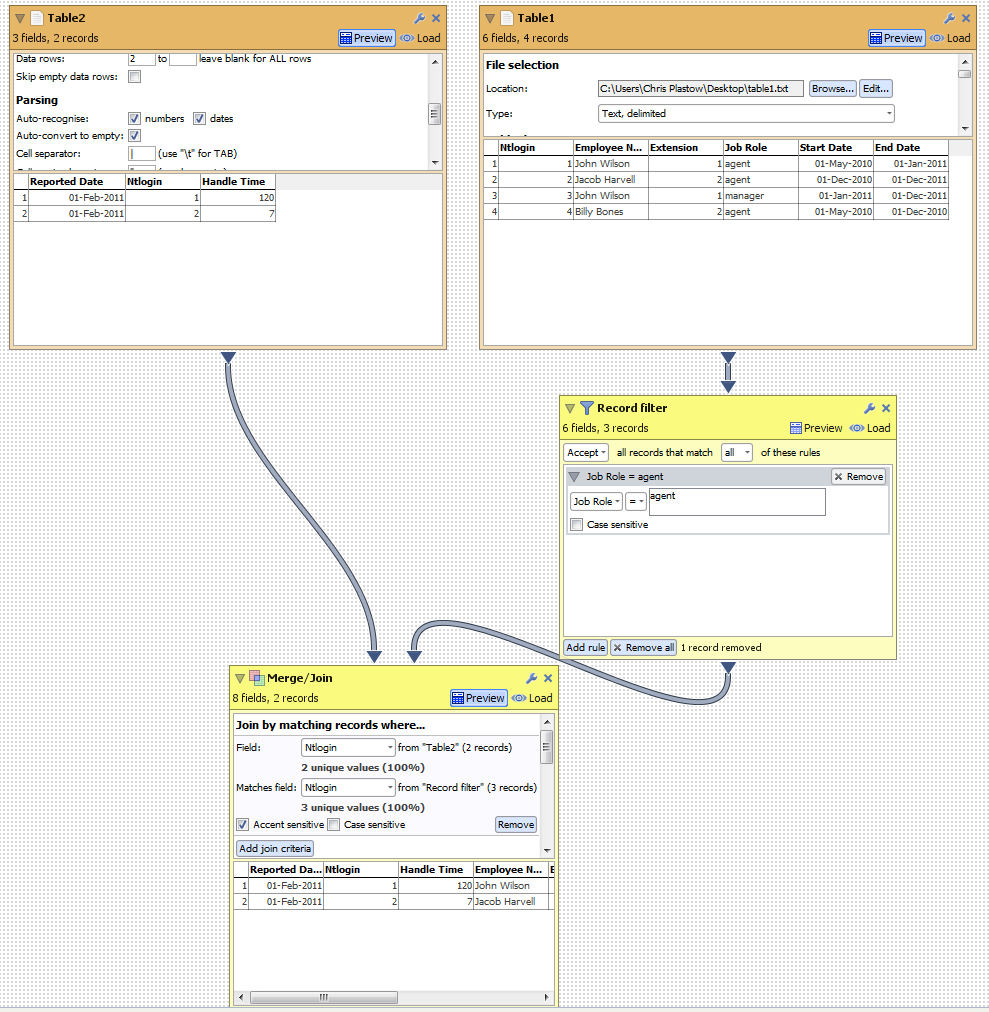
joinexample.png 81K -
I don't think I follow your example, if you could expand it might prove helpful.
I currently have been doing it like:
* Append Table_1 to Table_2
* Create a formula titled AGENT and do something like UNIQUE_LIST(INTERSECTION(SUBSET([SOURCE],"Table_1","="),SUBSET([NTLOGIN],[NTLOGIN],"="),SUBSET([START_DATE],[REPORTED_DATE],"<="),SUBSET([END_DATE],[REPORTED_DATE],">=")))
* Record Filter to remove records where source is Table_1.
The problem for me is that I have to make a *lot* of these types of correlations where its not a direct match between telephony, incident, self service, change request data. When doing an intersection of 3-5 subsets for a combined total of over 700k records - well it gets timely. As we speak I have a machine with 16GB RAM and 2 3.0Ghz xeons eating at this one formula on two different data sets for about 45mins.
The same operation using a more complex left outer join in SQL takes under 5mins to perform so I wasn't sure if it would be beneficial to investigate.
Thanks again,
-John -
Note: You might find INTERSECTION(...) to be slow. This is an experimental new function which hasn't been optimised yet. Using INTERSECTION(sub1, sub2, sub3), for example, is equivalent to using SUBSET3(...), but SUBSET3 will perform much better for large datasets.
-
Steve, thanks for the note. Once optimization has been completed - will INTERSECTION be equivalent to the prior SUBSETX functions or exceed them? If the same - then I will back track my heavier files and replace them with the legacy functions but if it will surpass them in performance - I'll just hang tight.
Also, on the note of merge/join options - do you think there is any possibility of these in the future? I have a number of situations where I have to pair service in two different tools to a single user event based upon proximity in time and username which always ends up in a unique_list or record_count of SUBSET3 or SUBSET4 functions.
Thanks,
-John -
John, INTERSECTION is purely a flexibility and ease-of-use improvement. By combining intersections and unions you can create much more complex subset definitions, yet in a far simpler way (SUBSET3 for example is quite convoluted due to the complex parameter order).
I do not expect the equivalent INTERSECTION(sub1, sub2, sub3) to be any faster than SUBSET3(...) in the near future. However, as well as bringing INTERSECTION up to the same speed, we may improve the speed of both in future.
INTERSECTION will be performance-complete in 2.7, or 2.8 at the latest.
Yes, indeed there is a possibility of this. The 'agent' choice can be satisfied using Record Filter upstream. As far as I can tell, all else you need is the ability to choose an operator (e.g. less-than) for each join criteria / pair of fields (currently, this is fixed at "=" with additional text options for case/accent sensitivity). This will be prioritised according to how much interest (i.e. votes & comments) we get for it. So cast yours!


{kind=link}
Welcome!
It looks like you're new here. If you want to get involved, click one of these buttons!
Categories
- All Discussions2,595
- General680
- Blog126
- Support1,177
- Ideas527
- Demos11
- Power tips72
- 3.0 preview2
To send files privately to Visokio email support@visokio.com the files together with a brief description of the problem.