
PDF Output: Setting PDF encoding in a batch output
-
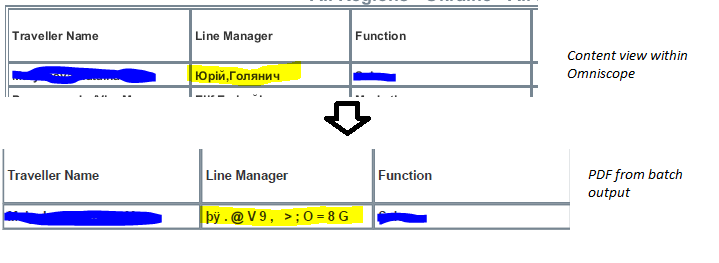
We are currently producing PDF files using a batch output. The data used to populate the PDF is a mix of character sets and as a result we have encoded this as UTF-8 during the load process. The data appears to be fine when viewed in the underlying database, datamanager and omniscope content view. However, when the PDF is rendered it does not encode the Cyrillic character set properly.
Is there a way we can set some options in the batch output configuration to set the content type properties of a PDF to default to UTF-8?Attachments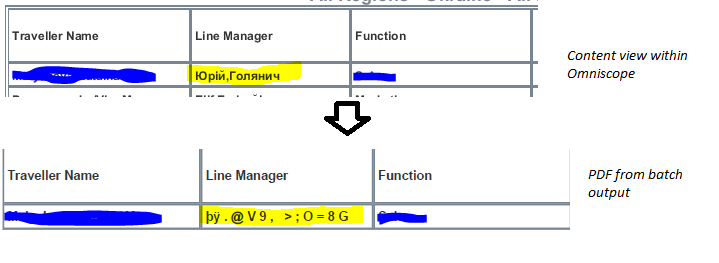
pdfencoding issue.png 13K -
1 Comment
-
This will take some investigation. Please could you create or narrow down a test case to be as few pages as possible (probably 1, although there's a possibility it might only happen with 2+ page PDFs), and as few visual elements (views) as possible? Then post or send me the IOK file. This will take out a lot of guesswork when trying to reproduce this.


{kind=link}
Welcome!
It looks like you're new here. If you want to get involved, click one of these buttons!
Categories
- All Discussions2,595
- General680
- Blog126
- Support1,177
- Ideas527
- Demos11
- Power tips72
- 3.0 preview2
Tagged
To send files privately to Visokio email support@visokio.com the files together with a brief description of the problem.