
Poll: Improving Text Mining Capabilities?
-
5 Comments
-
Exciting!
I mostly use tm and opennlp in R. Other tools that I have dabbled with include GATE, @note2. I like the fact that tm can import text from many sources, like existing dataframes, directories, etc. I also use the XML and JSON libraries.
I like the fact that these tools are generally free of charge and that they have excellent documentation.
Tasks that are important to my business: term-vector text mining, especially dictionary-based. Named entity extraction and relationship extraction. -
It'd be good to have the possibility to extract words (a list of words separated by a comma) that fulfill certain regular expression. I currently do it with R, but I'd preffer something cleaner.
-
Carlos: We have already extended existing RegEx filtering to include Search/Replace as described here:
http://forums.visokio.com/discussion/2457
You may be able to use this to 'flag' records containing matches that fulfill your Regex, and/or to re-write the matches in a more useful/filterable/exportable way.
You can change any Sidebar filter device set to Text Search to apply RegEx by choosing 'Show Text Tools' then choosing 'Search Type > Regular Expressions'. -
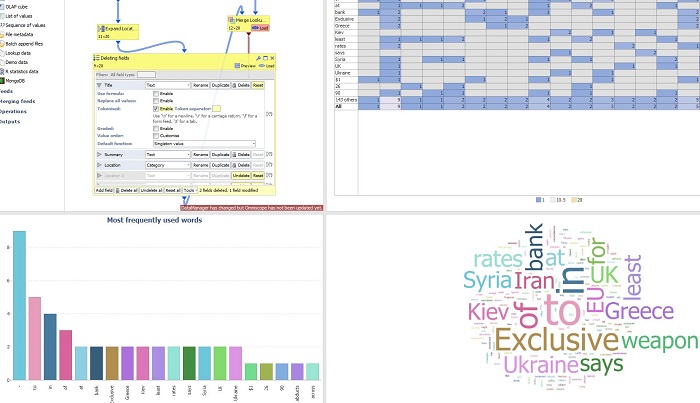
Suggestion... depending on the complexity of your Regex filtering...You could replace the criteria with multiple Record filter block rules, Search/Replace the spaces with commas, tick the option that field is tokenised and get the field where each word will be treated as an individual value.
You can use this field now to create charts e.g. most frequently used word bar view, word cloud visualisation (the Tag View), Pivot view to identify the combinations - table showing how many times words appeared in combination with other words.
Please see the demo file with few of these ideas.
You can also have a look at the Text-mining block tutorial video http://tc.visokio.com/videos/?name=DataManagerTextMine&title=Text+mine&lang=gb
 Attachments
AttachmentsTokenised.JPG 84K 
Tokenised_ReutersNews.iok 76K



{kind=link}
Welcome!
It looks like you're new here. If you want to get involved, click one of these buttons!
Categories
- All Discussions2,595
- General680
- Blog126
- Support1,177
- Ideas527
- Demos11
- Power tips72
- 3.0 preview2
Tagged
To send files privately to Visokio email support@visokio.com the files together with a brief description of the problem.