
Import: Load only first 1000 records?
-
Hi All!
I'm new to Omniscope. Is there a way to load only the first 1000 top rows of a file? When developing/testing and I don't want to work with the complete file. At the moment, I'm working with a .csv file that contains 1,4M rows just for one month and it takes forever to load this.
Cristian -
6 Comments
-
Probably best to load that amount of data into a database and use one of the database query connector to load snippets of data. You can do this with any SQL databases, R will also have that functionality if you install the right R library for parsing data with.
Also if it's just for testing, why not just manually extract a 1000 of your data and use that? -
Sure, just use a Random Sample block (in the DataManager Operations menu) and set the sample size to 1,000 to pick random records.
If you wish to see the first 1000 records - you can use the Record filter operation and set Record number less than 1001. You could also try to sort the records by value in a field X, by using the Sort block, and then apply the same record filtering step as above. -
OK. At the moment I'm using .csv files and I could of course just manually extract 1000 rows of data. Thought there might be another way of doing this, i.e. in the data file block.
If I use the random sample block I would have to load 1,4M rows first and then throw away data - same problem that I have now paola - I use the filter block to "throw away" the data but still I load 1,4M rows.
Any way thank you for your fast response!
Br
Cristian -
In block configuration select the data rows you want to use, see attached screenshot.Attachments
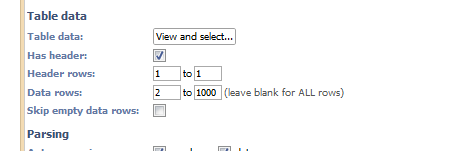
datarows.png 5K -
Paola's suggestion will give you a random sample accross all 1.4M rows, however it will still require the Data file block to load before the random sample can be calculated. If you select the data rows in the source block it will be the first 1000 rows (not a random sample) but should load much quicker.




{kind=link}
Welcome!
It looks like you're new here. If you want to get involved, click one of these buttons!
Categories
- All Discussions2,595
- General680
- Blog126
- Support1,177
- Ideas527
- Demos11
- Power tips72
- 3.0 preview2
Tagged
To send files privately to Visokio email support@visokio.com the files together with a brief description of the problem.