
New: Sources-MongoDB Database Connector
-
There is growing interest in noSQL databases in our organisation, and specifically MongoDB.
Would be useful if Omniscope could hook directly to the data stored in MongoDB repositories...
Anyone else interested?
https://www.mongodb.org/ -
13 Comments
-
We certainly plan on providing noSQL support in Omniscope. However there is great flexibility in how data is stored within such databases.
It would help if you could outline a few use cases, with detail on the low-level data structure of the keys and documents, and which aspects you'd want to extract to visualise or do ETL with, and how you might query/filter the data at source.
-
Using a trial database have managed to get MongoDB data into an R module and then into Omniscope.
Test script in R is very simple:
library(RMongo)
mongo<-mongoDbConnect("test","tstldnvl22mgo1",27017)<br />output_data <- dbGetQuery(mongo,"bundles",'{"bundleId":"891334"}')<br />
It's a start
-
The data we have used has information on batches of trades per client. Each document has one trade batch with a date and clientname and then a collection of trades. Each trade is a collection of field/value pairs.
Data comes into omniscope as text or number fields.
Once in I have used field splitting, pivot/depivot and text cleaning to flatten it out. -
Hi Bernard,
Thanks for sending us the sample data. We are still in the process of collecting requirements for the MongoDB connector and are trying to obtain as many sample datasets as possible.
The structure of the data inside MongoDB means that it's development is not as straightforward as other traditional databases. In MongoDB data is stored/retrieved as JSON. This means we need to convert the JSON tree structure into a tabular structure supported by Omniscope. We have discussed various ways of doing this and have done some experimentation, but before proceeding we need to be sure that we create a connector that provides the flexibility to support all the different ways that users might structure their data. This is why it is imperative that we obtain as many use cases as possible to ensure we cover all bases.
Unfortunately I cannot provide any exact timescales on it's development, but we are hoping to deliver a connector sometime in the next few months. If this is something that is urgent please contact us directly.
Thanks again for your help so far.
Chris
-
Hi Maxime,
We are in the process of developing a MongoDB connector in Omniscope and hope to make it available in Omniscope 3.0 alpha in the next few weeks. We will announce the connector formally on the forums, but in the meantime please let us know if you would like to help us test the connector prior to it's release. -
We have a first Omniscope build with the MongoDB connector and publisher, and it is available for download:
http://www.visokio.com/download/?branch=beta-rc&feature=Hotfix_MongoDB_connector
This is a feature release build that is still being tested. If you want to help us test it please feel free to download and install it.
You will need to have a MongoDB server installed. If you don't have it, you can download a MongoDB release from http://www.mongodb.org/downloads, it can be installed on most OS platforms (Windows, Linux, Mac OS X, Solaris).
MongoDB connector requires you to specify the
1. Host name, or IP of the machine running MongoDB,
2. Port (default is 27017),
3. Database name and
4. Authentication details if the database has been added users with roles to access the database. If no user has been set up, you can access it as an anonymous user.
5. Once the connection is being established, the list of current collections is populated.
6. Skip and Limit values are set on the MongoDB query cursor, by default Skip is 0 - meaning that no documents will be skipped, Limit is the number of documents in the collection.
7. MongoDB collections have BSON documents which are in fact JSON strings with small additions. JSON has a tree structure, like XML documents and therefore a mapping is applied on each document to transform it to a tabular (table with rows and columns) form. Just like XML file import there is a custom mapping field allowing the user the customize and change the transformation of the JSON string.
MongoDB connector is located in DataManager -> Blocks -> Sources
MongoDB publisher allows the user to publish Omniscope data to a MongoDB database.
To add a new MongoDB publisher you need to specify the
1. Host name or IP of the machine running MongoDB
2. Port, database name, authentication details
3. A collection name. If the collection does not exist, it will be created automatically.
4. Publish method
MongoDB publisher is located in DataManager -> Blocks -> Outputs
Please check it and let us know if you like it, find it useful, or have any feedback.
Also, please let us know if you see any issues.
Thank you,
Slavvi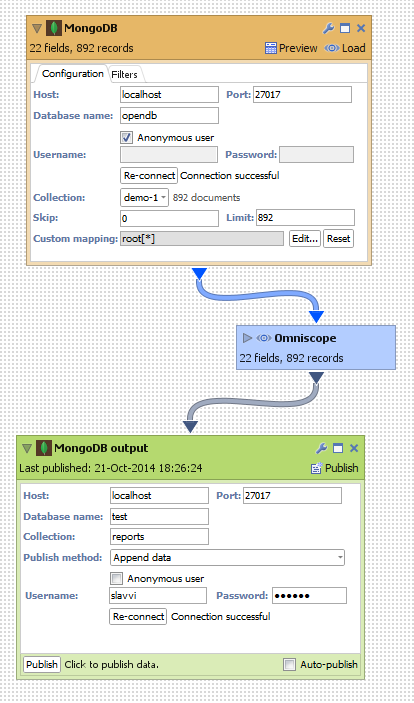 Attachments
Attachmentsdemo.png 42K -
I can can read the data from MongoDB but am having problems flattening out a document with an array. The default mapping creates the record of the main document and repeats it once for each item in the array but doesn't put any of the array field in the record.
If I select one of the array fields in the record column of the mapping then only those records with an entry for that field are created, and only that field value is carried through, all the other fields have blank entries.
Is there a way to get a flattened view with all the fields in the array used and all values present for each entry filled in.


{kind=link}
Welcome!
It looks like you're new here. If you want to get involved, click one of these buttons!
Categories
- All Discussions2,595
- General680
- Blog126
- Support1,177
- Ideas527
- Demos11
- Power tips72
- 3.0 preview2
Tagged
- data_sources29
- version_3.023
- MongoDB1
- NoSQL1
- mongodb1
- nosql1
To send files privately to Visokio email support@visokio.com the files together with a brief description of the problem.