
Integration: Merge/Join on first match only?
-
I think it might be useful to have an option in the merge/join block to only merge the first match.
Here is what I'm trying to do. I have a field containing a string of text which sometimes contains place names. I wish to match up the place names in this text string with the list of place names in the lookup data built in the data sources. Because it's a string of text I'm using the "contains" criteria in the merge/join block but this means that manchester and chesterfield will match chester. There are many other instances of this happening, too many to sort out manually.
If I sorted the data so that place names which contained other place names were at the top, and then I could merge the first match then I think this would solve this problem. Is this a possibility for future releases?
In the mean time can anyone think of a way round this?
Thanks, Martin -
2 Comments
-
Create two branches from your Merge block, leading to two Field Organisers.
In one preserve the field you wish to de-duplicate and uniqueID field, in the other everything but the field with repetitive values (here Month).
Use De-duplicate block to get rid of the duplicates in the target field, then merge with other Field organiser on uniqueID field, preserving the non-matching records from the second block.
See image: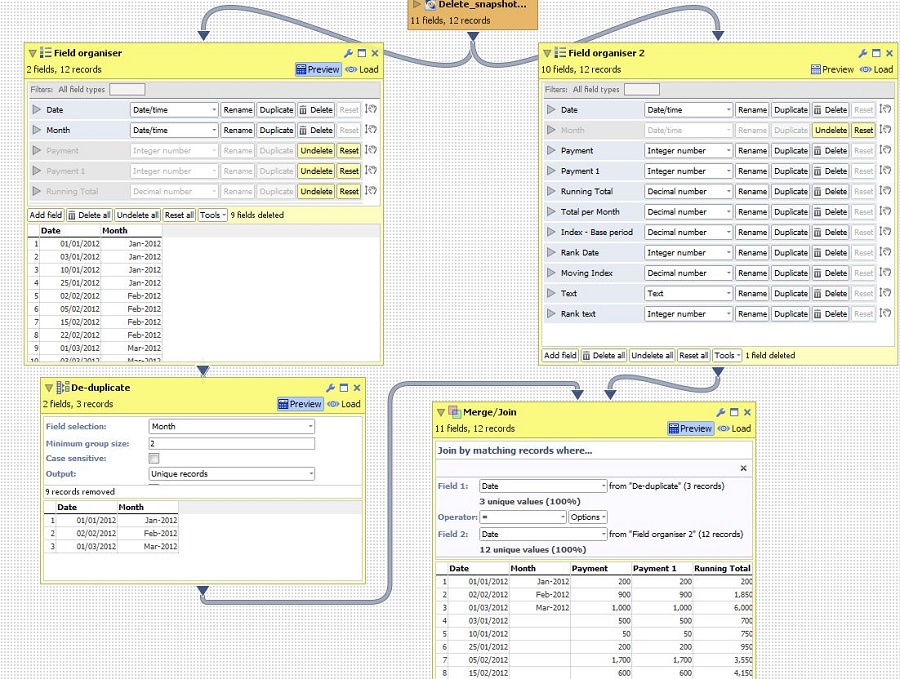 Attachments
AttachmentsDe-duplicate.JPG 259K

{kind=link}
Welcome!
It looks like you're new here. If you want to get involved, click one of these buttons!
Categories
- All Discussions2,595
- General680
- Blog126
- Support1,177
- Ideas527
- Demos11
- Power tips72
- 3.0 preview2
Tagged
To send files privately to Visokio email support@visokio.com the files together with a brief description of the problem.