
Performance: Importing from CSV...any memory guidelines?
-
Hi. I am running Omniscope on a computer with only 4 GB of physical memory. I am trying to process a CSV file with about 5.4 million records (rows) in it and 15 fields (columns). Omniscope is running out of memory. The File Source block gets to about 27% processing complete.
I have read other posts about users processing more than 5.4 million records, so I think it is quite possible for Ominscope to process this large file I have, right?
I have also read http://www.visokio.com/kb/omniscope-memory-allocation.
My main question is: are there any guidelines on how much memory Omniscope needs as a function of records/fields. I realize this is probably one of those many "it depends" situations, but even rough guidelines (+/- 1 or 2 GB) would help.
If there are no guidelines, can I send you my .iok file (there are only 6 blocks: a File Source block, 3 Field Organizer blocks, a Record Filter block, and a Expand Values block) and a sample of the input file, which you can expand to about 5 million records (or I can ftp the whole file), and you can run it and let me know how much memory Omniscope uses?
Thanks! Chris
-
9 Comments
-
It might be to do with whether or not your Omniscope is using Excel as a data reader. I know that it can sometimes cause memory problems and so you have to turn off the option. That is found in Settings->Advanced->Data Sources and using the alternative reader.
Personally I've only worked with 8GB setups and it goes upto 20 million rows at a push but probably for 100 fields. It isn't smooth running either and can be unresponsive with that amount of data.
I think it's actually better not to be working with csvs when you have million plus data sets and load the data up into a database and query off it. It's not too difficult to set up a local host database like postgresql and you can even use Omniscope to publish tables directly into a database. At the very least it's better data management and you can use database programs to work with your data too.
-
Thanks for the information Daniel!
So, if you have done 20 million rows of 100 fields with 8 GB of RAM, I should be able to do 5.4 million rows of 15 fields with 4 GB of RAM.
I will try using the alternate Excel file reader (POI), but I'm wondering if that will make a difference since I am reading a CSV file and not a .xls/.xlsx file. I would think Omniscope can read CSV files without needing to use Excel. Nonetheless, I'll give it a try and let you know.
In my initial post I forgot to mention I am running the 64-bit version of Omniscope 2.7, specifically build 459, on a Windows 7 machine.
-
OK. I switched to the alternate Excel file reader, and there was no noticeable difference. Omniscope read about 25% of the file, was using about 3 GB of RAM (its default limit on my system), and had slowed to a crawl.
I also did an experiment. I chopped the CSV file down to 1 million records, imported it, chopped it down to 0.75 million records, imported it, chopped it down to 0.5 million records, imported it, chopped it down to 0.25 million records, imported it. Here are the results for peak RAM used:
0.25 million records: 0.52 GB
0.50 million records: 1.06 GB
0.75 million records: 1.93 GB
1.00 million records: 2.98 GB
The trend is not linear.
The 17 fields (sorry... I was off by a couple of fields earlier) include 8 string fields, 8 real number fields, and one integer field. The string fields are not long... maybe about 10 characters on average.
I'll see if I can give the database approach a try. I am not doing queries, though. I need to process (transform) all the records and dump the transformed records to a new CSV file. I am wondering if loading the data from a database (instead of a CSV file) will reduce the RAM needed by Omniscope.
-
I can give it a test on a 8GB setup if you setup the ftp for it, also I can try loading it up on a postgresql server to see if that works any better.
Another possibility is to parse the file down into chunks (say 1 million per chunk), apply the processes to each individual chunk then create a separate process file to batch append them into one csv. If you have the Omniscope server licence it might be easier to do this on the scheduler. -
Thanks for the offer Daniel. As it turns out, the company I work for does not have an FTP site but instead uses Box.com. You would need to send me your email address so I can have Box.com send you an invitation to create a Box.com account and access the folder where the file will be. Is this OK with you? If you have a "drop box" account somewhere already, we can use that if you prefer. If you want to go the Box.com route, please send me your email address. I can be reached at christopher.mollo where the domain name is scenaria.com. Thanks!
-
I've tested the file and I loaded it up on my 8GB setup:
Overall my system was using about 7GB RAM (abut 6GB for Java and the other 1GB is the computer's normal processes)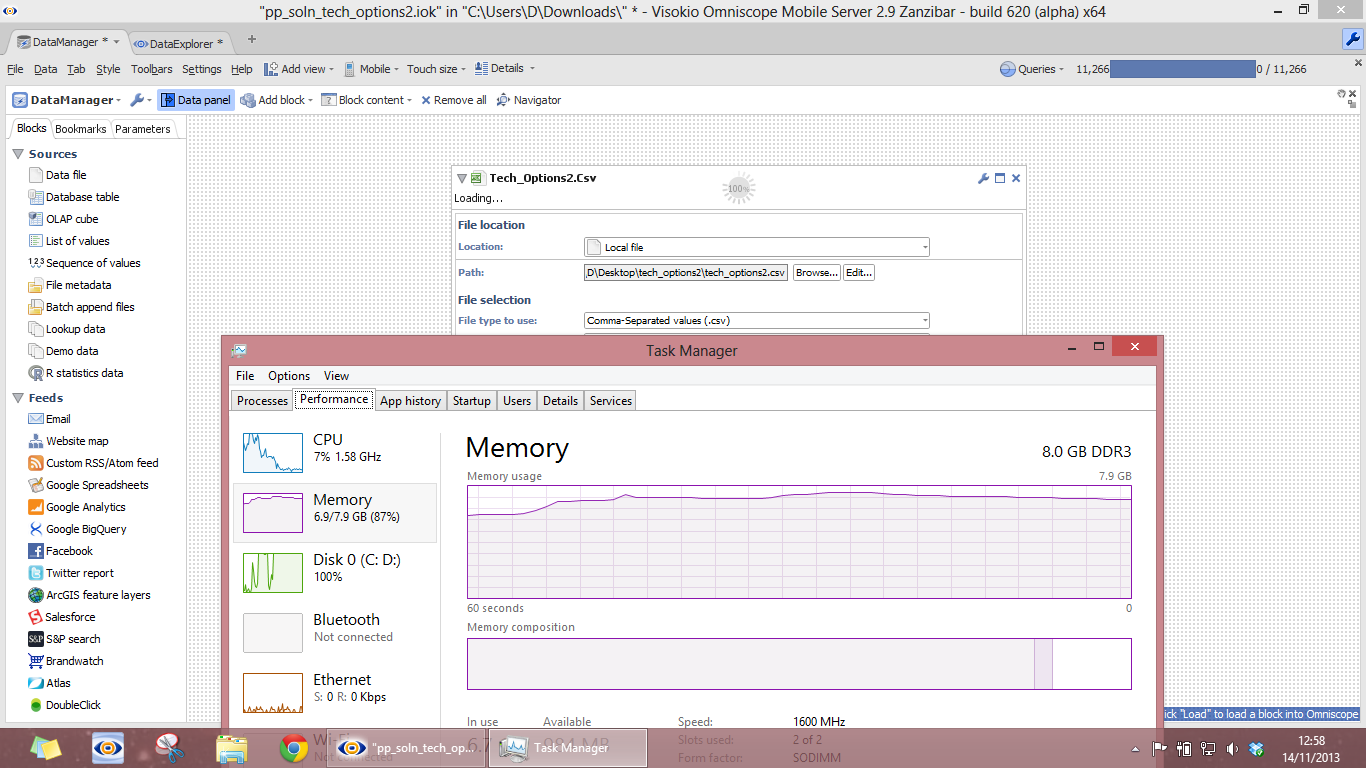
I don't necessary think that you must have 7GB though, it might process with less but taking more time. I'll try to cap the RAM on my machine and test for lower levels of 5 and 6 GB.
I also tried using a Postgresql database but that went over the 7GB when trying to connects and pull the full data set and used up nearly all my RAM and had a couple of unresponsive messages.
It did it but it is probably best not to use a database if you have to process the entire data set.
AttachmentsScreenshot (73).png 147K -
I repeated my test from before. Here are the new results (with "Recognize numbers and dates" options off):
0.25 million records: 0.45 GB
0.50 million records: 0.87 GB
0.75 million records: 1.56 GB
1.00 million records: 2.33 GB
About 20% reduction for the larger files.
I also discovered that in the File Source block I can exclude columns. There were a few columns with string type data in them that I did not need, so I excluded them in addition to turning off "Recognize numbers and dates" options. I have no dates in my data file, just numbers and strings.
For what I am doing with Omniscope, I never need all the data in memory. I wish Omniscope had an option to process (read, transform, write) the data row-by-row. Of course this would limit what one could do in Omniscope and there would be buffering for I/O, but if Omniscope had an option to work this way, then huge files could be processed with very little memory. I guess I will submit this on the "Ideas" discussion.



.png){kind=link}
Welcome!
It looks like you're new here. If you want to get involved, click one of these buttons!
Categories
- All Discussions2,595
- General680
- Blog126
- Support1,177
- Ideas527
- Demos11
- Power tips72
- 3.0 preview2
Tagged
To send files privately to Visokio email support@visokio.com the files together with a brief description of the problem.