The following example assumes that you already have an iGeolise Travel Time account. You can sign up for an account by clicking on "iGeolise account help" in the DataManager block noted below and following the link.
ATTACHMENTS
- Distribution centres.csv - A CSV file containing the locations of a company's distribution centres across London.
INSTRUCTIONS
- Create a new file in Omniscope and go to DataManager.
- Drag "Distribution centres.csv" onto the DataManager workspace.
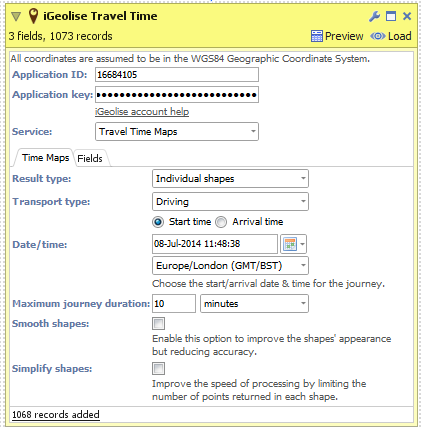
- Create a new "iGeolise Travel Time" operation and connect it to your workflow. This block will use the point data from the CSV and generate boundaries around each point to show how far can be travelled in a given time period.
- Enter your iGeolise Travel Time application ID and key.
- Choose the "Travel Time Maps" service.
- Change the "Transport type" to "Driving" so the service will calculate results based upon how far the company's delivery vans can travel by road.
- Enter a maximum journey duration, e.g. 10 minutes.
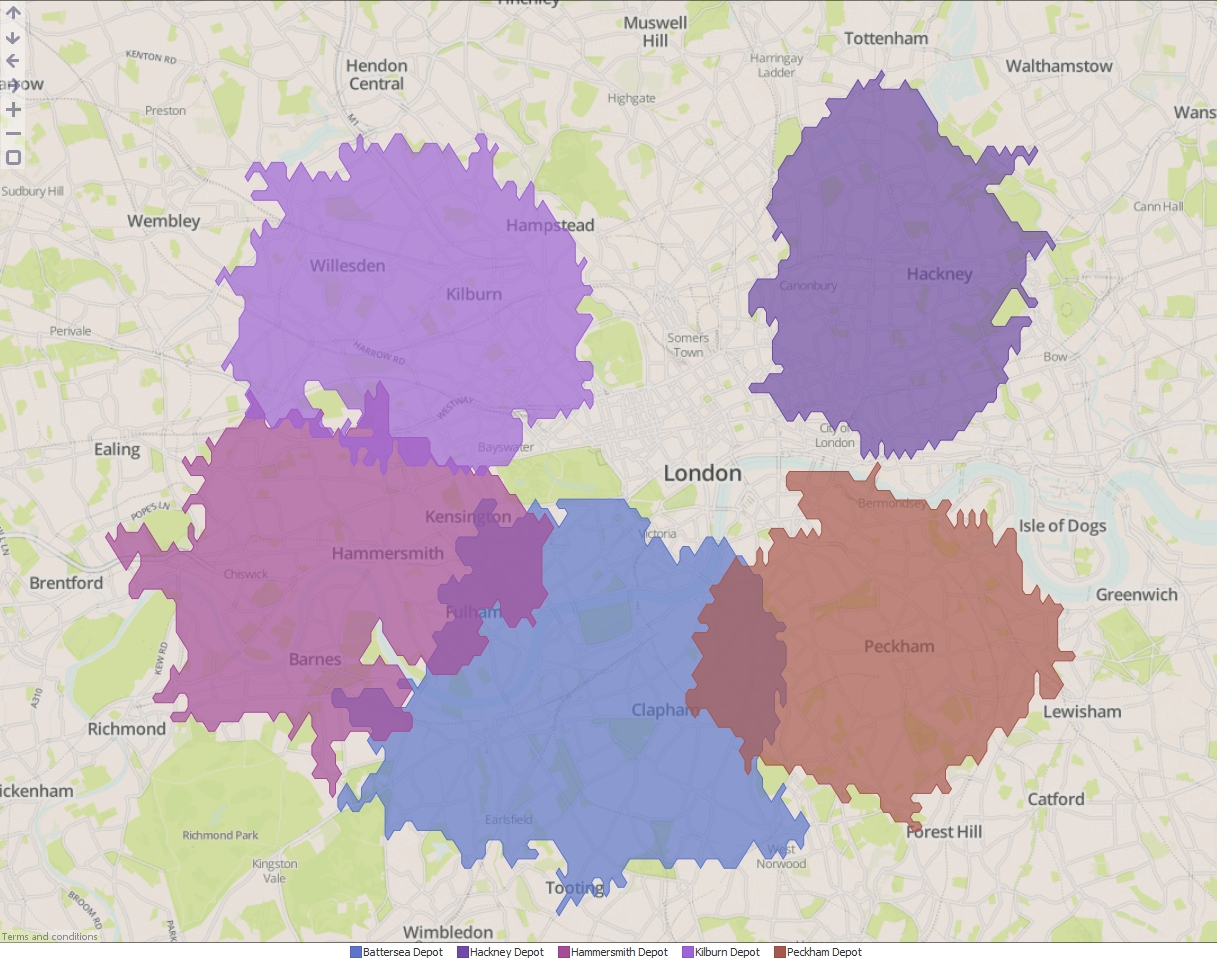
- You can change the "Result type" to show a separate shape for each distribution centre, merge all shapes into one or even intersect all the shapes to identify the cross-over areas.
- Execute the block, load the data into Omniscope and then drag a Map View into Omniscope to see the Time Maps.
ADVANCED
The "Travel Time Maps" service contains advanced options for configuring which fields contain contain the latitude/longitude values and the field for uniquely identifying individual points in the input dataset. If you are using KML or Shapefile sources then these fields will be configured automatically. Below are explanations for each option:
- Point identifier - Field containing unique identifiers for each point in the input dataset. In our example this would be the names of the distribution centres.
- Longitude - Field containing WGS84 longitude values.
- Latitude - Field containing WGS84 latitude values.
ATTACHMENTS
- "UK major cities.csv" - A CSV file containing the locations of major cities in the United Kingdom.
- "English postal areas.kml" - A KML file containing the boundaries of all postal areas in England.
INSTRUCTIONS
- Create a new file in Omniscope and go to DataManager.
- Drag "UK major cities.csv" and "English postal areas.kml" onto the DataManager workspace.
- In the "English postal areas.kml" block, next to "Overlay identifier", select "Name". This means that Omniscope will use the postal area names to uniquely identify postal area shapes in the data.
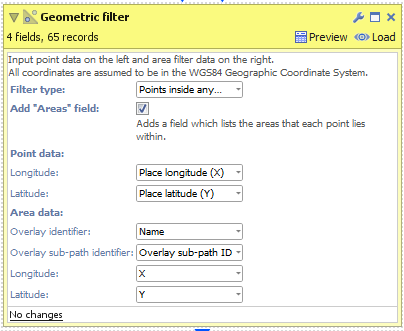
- Create a new "Geometric filter" operation. This block requires first a point dataset and second an area dataset to function. So connect the "UK major cities.csv", then the "English postal areas.kml" (please note that the point data must be connected first).
- Select a Filter Type:
- All points (don't filter) - All points will be returned from the block. Use this in conjunction with 'Add "Areas" field' (see next step).
- Points inside any area - Keep only the points which fall inside at least one area shape.
- Points outside all areas - Keep only the points which do not fall inside any area shape.
- Check 'Add "Areas" field' to add a new field and merge the "Overlay identifier" from the Area dataset into your new Point dataset. In our example this will add the postal area codes from the "English postal areas.kml" into the new cities dataset.
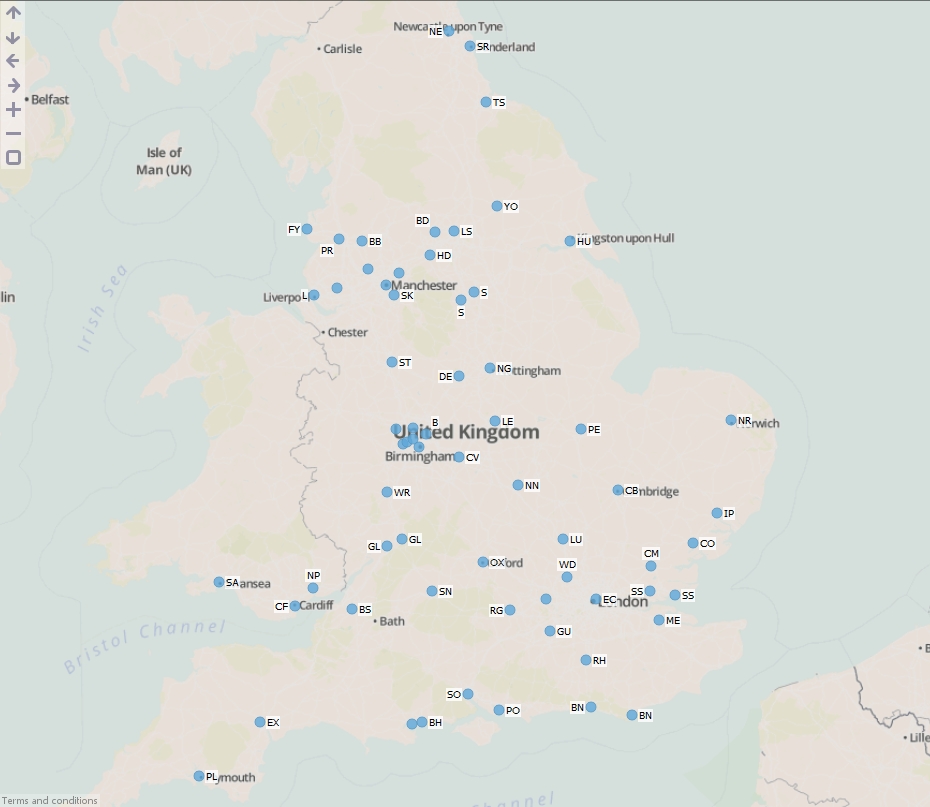
- Execute the block, load the data into Omniscope and then drag a Map View into Omniscope to see the filtered point data.
ADVANCED
The "Geometric filter" block also contains additional controls for configuring which fields contain the latitude/longitude values and the fields for identifying individual features (shapes) in the input dataset. If you are using KML or Shapefile sources then these fields will be configured automatically. Below are explanations for each option:
- Overlay identifier - Field containing unique identifiers for each point or area in the input dataset, e.g. a field containing country names or postal area codes.
- Overlay sub-path indentifier - This is used internally within Omniscope to identify nested geometries within each shape. For example a shape for the United Kingdom could not be drawn with one continuous line. We use this field to breakdown the records into numerous islands which make up the country.
- Longitude - Field containing WGS84 longitude values.
- Latitude - Field containing WGS84 latitude values.
Geometric buffers can be applied to 3 types of shape data in Omniscope;
- Point - A dataset containing pairs of latitude/longitude coordinates, e.g. a shop location.
- Line - A dataset containing connected, and unfilled/unclosed, chains of points, e.g. a hurricane path or road.
- Area - A dataset containing connected, and filled/closed, chains of points, e.g. a post code area or country border.
Below are instructions for buffering these 3 types of shape data. Please download and extract the contents of the ".zip" file:
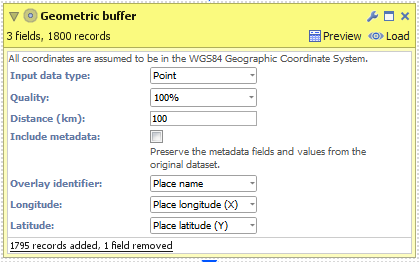
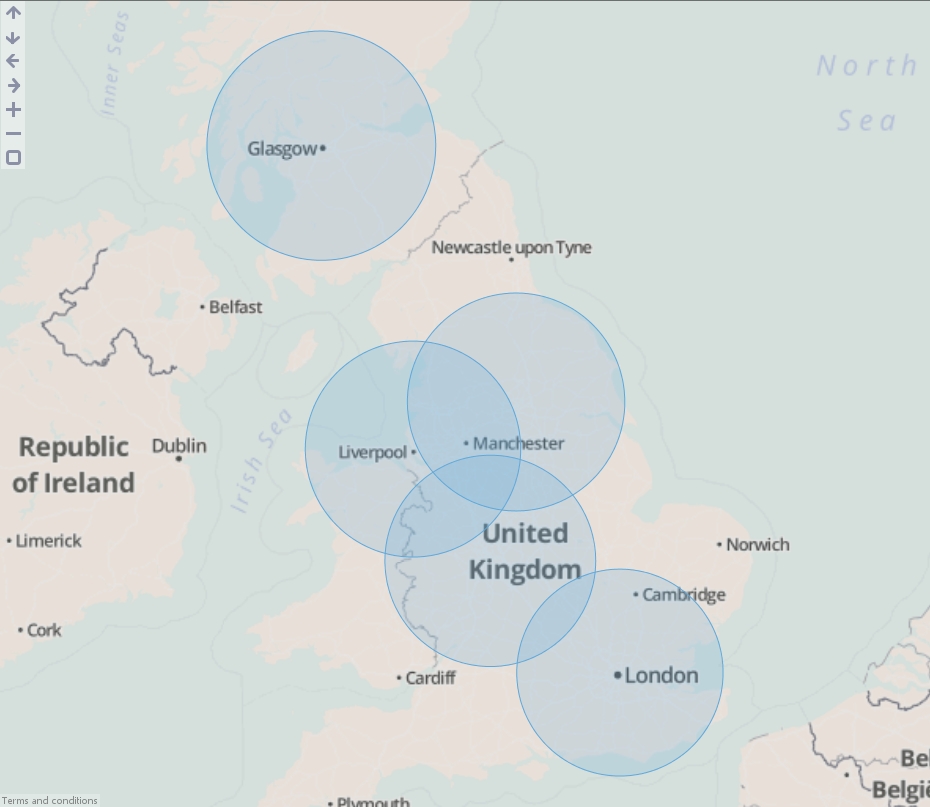
POINT
- Create a new file in Omniscope and go to DataManager.
- Drag "United Kingdom cities.csv" onto the DataManager workspace. This contains 5 major cities in the United Kingdom with latitude/longitude coordinates.
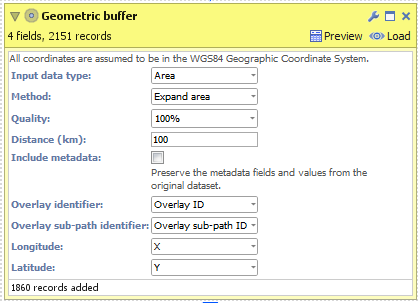
- Connect a "Geometric buffer" operation to the workflow.
- Choose "Point" as the "Input data type". (For KML and Shapefile sources, this will be configured for you.)
- Enter a distance (km) to buffer around each input point. By reducing the "Quality" you will increase the speed of this block but the output dataset will contain less records and the buffered outline will not be as smooth.
- Check 'Include metadata' if you would like the output dataset to contain all other fields found in the input, i.e. "Country name".
- Execute the block, load the data into Omniscope and then drag a Map View into Omniscope to see the buffered points.
LINE
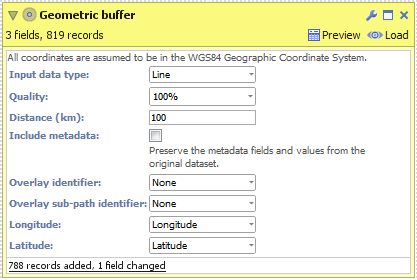
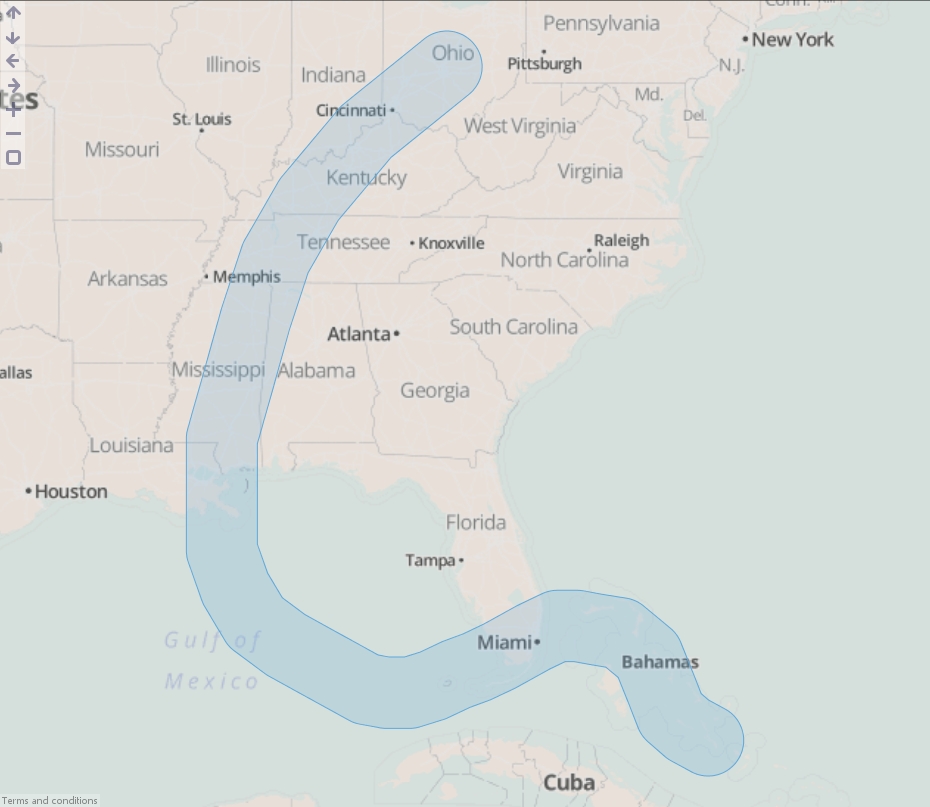
- Create a new file in Omniscope and go to DataManager.
- Drag "Hurricane Katrina.csv" onto the DataManager workspace. This contains coordinates for the path of Hurricane Katrina in 2005.
- Connect a "Geometric buffer" operation to the workflow.
- Choose "Line" as the "Input data type". (For KML and Shapefile sources, this will be configured for you.)
- Enter a distance (km) to buffer around the line (hurricane path). By reducing the "Quality" you will increase the speed of this block but the output dataset will contain less records and the buffered outline will not be as smooth.
- Execute the block, load the data into Omniscope and then drag a Map View into Omniscope to see the buffered line.
AREA
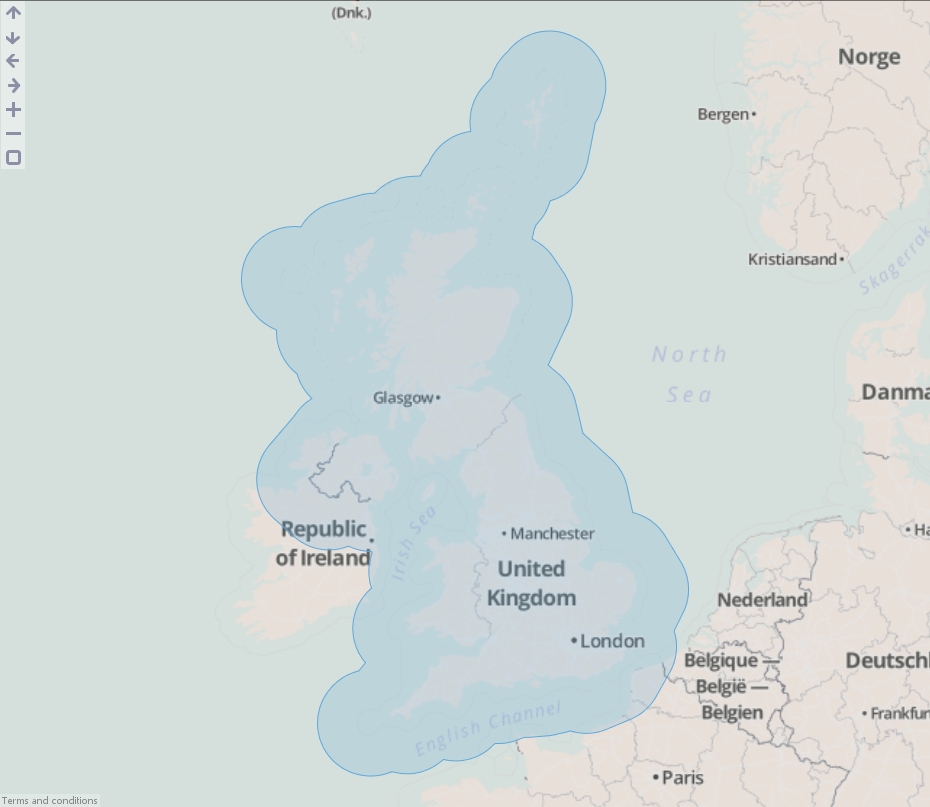
- Create a new file in Omniscope and go to DataManager.
- Drag "United Kingdom.kml" onto the DataManager workspace. This contains coordinates defining a simplified boundary of the United Kingdom..
- Connect a "Geometric buffer" operation to the workflow.
- Ensure "Area" is selected as the "Input data type". (For KML and Shapefile sources, this will be configured for you.)
- Choose your method of buffering:
- Expand area - The original area plus an outside perimeter.
- Contract area - The original area less an inside perimeter.
- Outside perimeter - The area within a certain distance outside of the perimeter.
- Inside perimeter - The area within a certain distance inside of the perimeter.
- Outside + inside perimeter - The area within a certain distance either side of the perimeter.
- Enter a distance (km) to buffer around the United Kingdom. By reducing the "Quality" you will increase the speed of this block but the output dataset will contain less records and the buffered outline will not be as smooth.
- Execute the block, load the data into Omniscope and then drag a Map View into Omniscope to see the buffered line.
ADVANCED
The "Geometric buffer" block also contains additional controls for configuring which fields contain the latitude/longitude values and the fields for identifying individual features (shapes) in the input dataset. If you are using KML or Shapefile sources then these fields will be configured automatically. Below are explanations for each option:
- Overlay identifier - Field containing unique identifiers for each point, line or area in the input dataset, e.g. a field containing country names or postal area codes.
- Overlay sub-path identifier - This is used internally within Omniscope to identify nested geometries within each shape. For example a shape for the United Kingdom could not be drawn with one continuous line. We use this field to breakdown the records into numerous islands which make up the country.
- Longitude - Field containing WGS84 longitude values.
- Latitude - Field containing WGS84 latitude values.
- Esri (batch) - Returns the highest ranking match per location. More efficient for large datasets than using Esri multi-match.
- Esri (multi-match) - Can return multiple matches per specific place name, e.g. a place called "Aberdeen" exists in Scotland, Hong Kong etc.
- Yahoo - Yahoo BOSS PlaceFinder.
Each of these services requires an account with the relevant service provider. Links to the provider's sign-up page are included in the Geocode block.
INSTRUCTIONS
- Create a new file in Omniscope and go to DataManager.
- Add a 'List of values' block to the DataManager workspace and insert some values (to test the feature) or use a dataset that already has a location field.
- Connect a Geocode block to your workflow, select the field "Values" (containing your place names) and choose a geocoding service:
- Esri (batch)
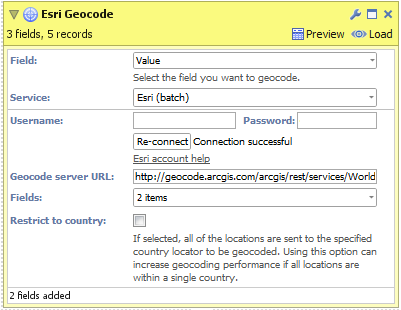
- After signing up for an account, enter your username and password then click 'Connect'.
- Select the fields you want the geocoding service to return.
- Click "Restrict to country" if all of your place names exist within a single country. This can improve the accuracy of geocoded results.
- Click "Execute" to begin geocoding.
NB: "Geocode Service URL" is an advanced option for overriding which Esri geocoding service Omniscope will use to generate results. - Esri (multi-match)
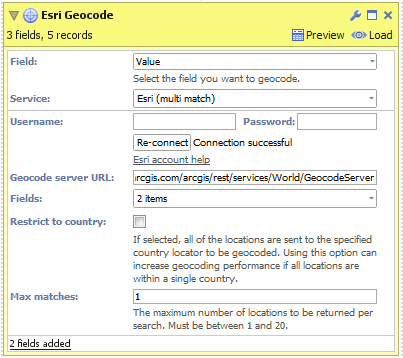
- After signing up for an account, enter your username and password then click 'Connect'.
- Select the fields you want the geocoding service to return.
- Click "Restrict to country" if all of your place names exist within a single country. This can improve the accuracy of geocoded results.
- Configure "Max matches" to select how many results you would like returned for each input place name.
- Click "Execute" to begin geocoding.
NB: "Geocode service URL" is an advanced option for overriding which Esri geocoding service Omniscope will use to generate results. - Yahoo
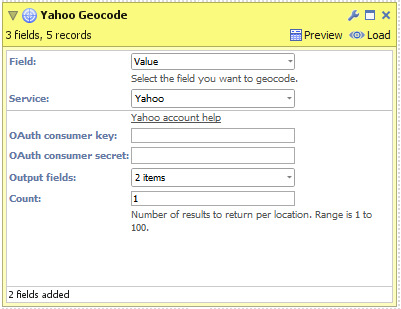
- After signing up for an account, enter your OAuth consumer key and secret then click 'Connect'.
- Select the fields you want the geocoding service to return.
- Configure "Count" to select how many results you would like returned for each input place name.
- Click "Execute" to begin geocoding.
- Esri (batch)
- Load the data into Omniscope to see the geocoded place names and visualise the data in the Map View.
ATTACHED FILES
- "postcode areas.shp" (inside ZIP) Contains geometries for each feature (shape) in the Esri Shapefile
- "postcode areas.dbf" (inside ZIP) Contains meta-data for each feature (shape) in the Esri Shapefile
- "postcode areas.prj" (inside ZIP) Contains the coordinates' projection, e.g. UTM, WGS84.
INSTRUCTIONS
- Download the attached ".zip" file and extract the ".shp", ".dbf" and ".prj" files into the same folder.
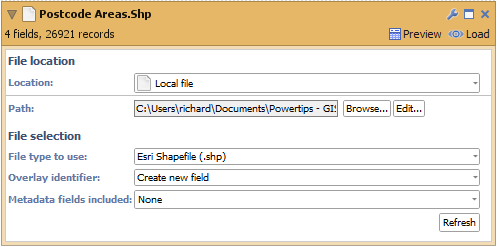
- Create a new file in Omniscope and go to DataManager.
- Drag the "postcode areas.shp" file onto the DataManager workspace (or drag a "Data file" block onto the workspace and browse to the "postcode areas.shp" file). The ".dbf" and ".prj" files will be automatically detected.
- The Esri Shapefile DataManager block contains 2 configurable options
- "Overlay identifier" - The field which contains unique identifiers for each feature (shape) in the file. In our Shapefile this would be the names of the postal areas, e.g. AB for Aberdeen, SW6 for South West London. If your data does not include such a field then selecting "Create new field" will allow Omniscope to generate internal unique identifiers using a field named "Overlay ID".
- "Meta data fields included" - The names of all fields which will be loaded from the Esri Shapefile into the block.
- Load the data into Omniscope then drag a Map View into Omniscope to see the postcode areas.
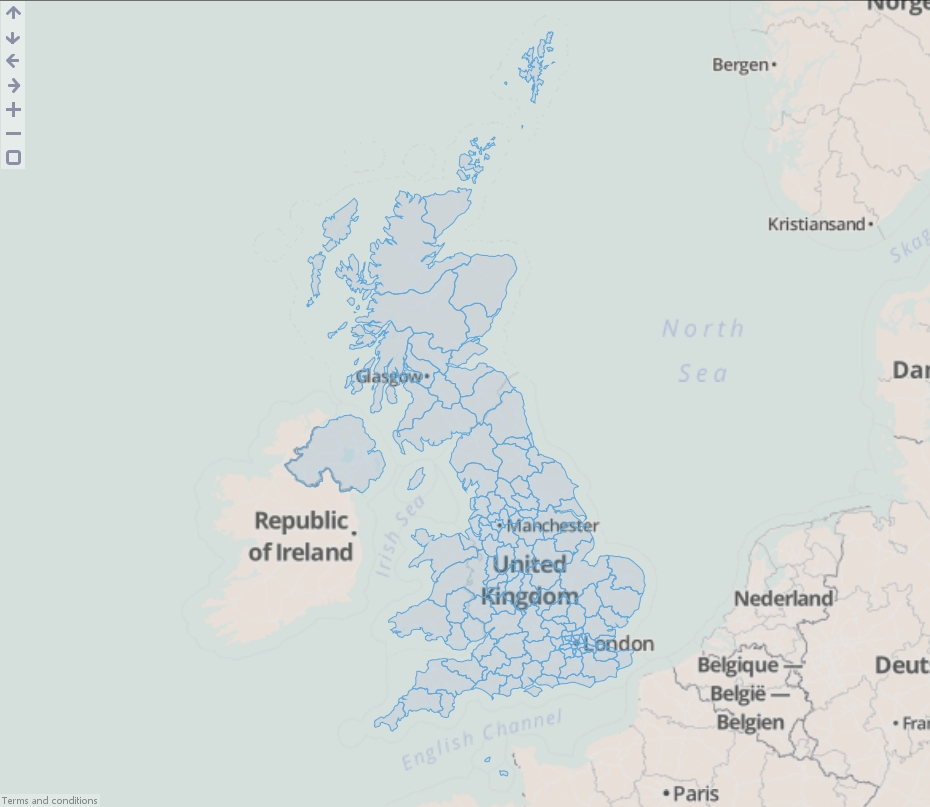
ADVANCED
You will notice a field has also been created named "Overlay sub-path ID". This is used internally within Omniscope to identify nested geometries within each shape. For example a shape for the United Kingdom could not be drawn with one continuous line. We use this field to breakdown the records into numerous islands which make up the country.]]>
ATTACHED FILE
- "postcode areas.kml" (inside ZIP) Contains geometries and meta-data for each feature (shape)
INSTRUCTIONS
- Download the attached ".zip" file and extract the ".kml" file.
- Create a new file in Omniscope and go to DataManager.
- Drag the "postcode areas.kml" file onto the DataManager workspace (or drag a "Data file" block onto the workspace and browse to the "postcode areas.kml" file).
- The KML DataManager block contains 3 configurable options:
- "Overlay identifier" - The field which contains unique identifiers for each feature (shape) in the file. In our KML file this would be the names of the postal areas, e.g. AB for Aberdeen, SW6 for South West London. If your data does not include such a field then selecting "Create new field" will allow Omniscope to generate internal unique identifiers using a field named "Overlay ID".
- "Meta data fields included" - The names of all fields which will be loaded from the KML file into the block.
- "Shape types included" - KML files can contain a combination of points, lines and areas. Use this option to filter which shape types you want to load.
- Load the data into Omniscope then drag a Map View into Omniscope to see the postcode areas.
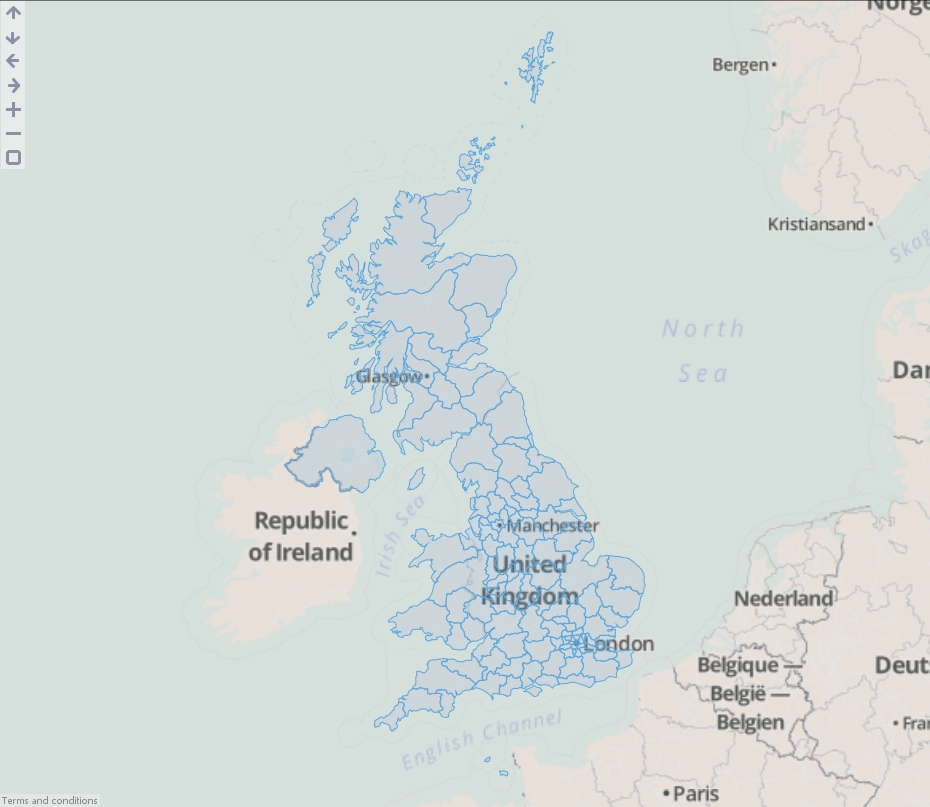
ADVANCED
You will notice a field has also been created named "Overlay sub-path ID". This is used internally within Omniscope to identify nested geometries within each shape. For example a shape for the United Kingdom could not be drawn with one continuous line. We use this field to breakdown the records into numerous islands which make up the country.]]>
One of our regular reports has approximately 40 queries. Unfortunately this clutters up the filters as although the top ~10 queries are used commonly, the remaining ~30 queries (predominantly used for tables tailored to specific user requirements) are also displayed and this pushes down the other filters on the right sidebar. Some people who view this report do not realise that they need to scroll down to find the other filters.
We would like to be able to group these queries, i.e. into a 'general queries' and a 'table queries' group so that we may collapse the options available in the filters.]]>
Rank function Syntax: RANK(value, field, isAscending, includeNulls, dataSubset)
Ranking Spend=
RANK([Spend])
# simple Rank comparing all values in the Spend field
Rank Spend per Week=
RANK([Spend], [Spend], false, false, SUBSET([Week]))
#Ranking Spend values inside each Week
SubRank Clicks =
RANK([Clicks], [Clicks], false, false,subset([Rank Spend per Week] ))
# secondary rank field, based on the Clicks value. Meaningful when multiple rows share the same [Rank spend per Week] value
Spend per Keyword=
SUBSET_SUM([Spend], SUBSET([Keyword]))
# total Spend for each Keyword
[One]=1
# basis for running total indexing
Running total per Keyword:
RUNNINGTOTAL([One], SUBSET([Keyword]))
Rank Totals per Keyword=
IF([Running total per Keyw]>1, null,
RANK([Spend per Keyword], [Spend per Keyword], false, true, SUBSET([Running total per Keyw],1,"=")))
# ignoring the values greater than 1, rank compares only the subset sum values where [Running total per Keyw] is 1, ensuring that only one value per category is compared. ]]>
Server SSL Error - handshake alert: unrecognized_name
You may get this SSL error if the server you are trying to access has not been properly configured.
For security reasons SNI extension has been enabled by default in Java 7. However, if you trust the server you are trying to connect you may want to disable SNI extension.
jsse.enableSNIExtension is a java system property. Server Name Indication (SNI) is a TLS extension, defined in RFC 4366. It enables TLS connections to virtual servers, in which multiple servers for different network names are hosted at a single underlying network address.
Some very old SSL/TLS vendors may not be able to handle SSL/TLS extensions. In this case, set this property to false to disable the SNI extension.
To disable SNL extension you need to do the following:
1. Open 'installconfig.properties' file located at {YOUR_OMNISCOPE_INSTALLATION_PATH}
{YOUR_OMNISCOPE_INSTALLATION_PATH} - this is where Omniscope is installed on your machine (e.g. C:\Users\slavvi\AppData\Local\Visokio Omniscope app)
2. Edit the file to add this line:
ADDITIONAL_JVM_ARGS=-Djsse.enableSNIExtension=false
3. Restart Omniscope
Note: After setting this property, you may get the following error if the server you want to access does not have a certificate issued by a certified authority:
The server you are connecting to does not have a valid certificate from an authorised authority
To resolve this error please read the following post:
http://forums.visokio.com/discussion/2613/security-the-server-you-are-connecting-to-does-not-have-a-valid-certificate
However, you will be unable to execute step 2 outlined in that forum post unless you disable the SNI extension while executing that command. Here is how that command may look like:
java -Djsse.enableSNIExtension=false InstallCert server-storing-my-iok-files.com:443
]]>
Server SSL error - The server you are connecting to does not have a valid certificate from an authorised authority
Here is what you need to do to enable Omniscope access the url you have (e.g. "https://server-storing-my-iok-files.com/"):
1. Download InstallCert.zip archive and unzip it (it contains two java class files: InstallCert$SavingTrustManager.class, InstallCert.class), put both of them in a folder (e.g. c:\your_path\)
2. Open command prompt (cmd.exe) and change current dir to the folder containing the class files from step 1 (e.g. cd c:\your_path\) then execute this command:
- java InstallCert server-storing-my-iok-files.com:443
Note: if you don't have java installed, use the java executable located at:
- {YOUR_OMNISCOPE_INSTALLATION_PATH}\x86\bin\java (if you have a 32 bit OS)
- {YOUR_OMNISCOPE_INSTALLATION_PATH}\x64\bin\java (if you have a 64 bit OS)
{YOUR_OMNISCOPE_INSTALLATION_PATH} - this is where Omniscope is installed on your machine (e.g. C:\Users\slavvi\AppData\Local\Visokio Omniscope app)
(to check whether you have a 32-bit or 64-bit OS: open Control Panel -> System and check 'System type:')
The command may look like this: "{YOUR_OMNISCOPE_INSTALLATION_PATH}\x64\bin\java" InstallCert server-storing-my-iok-files.com:443
If you get the SSL error - handshake alert: unrecognized_name while executing this command please read this post: handshake alert: unrecognized_name
3. You will be asked 'Enter certificate to add to trusted keystore or 'q' to quit: [1]', press 1 then press ENTER
Note: After executing step 3, this message will be displayed in the console:
Added certificate to keystore 'jssecacerts' using alias 'server-storing-my-iok-files.com-1'
which means that this particular certificate will be trusted by java applications if 'jssecacerts' keystore is provided
Notice that 'jssecacerts' file has been created in the folder you executed the command (e.g. c:\your_path\)
4. Open 'installconfig.properties' file located at {YOUR_OMNISCOPE_INSTALLATION_PATH}
5. Edit the file to add this line:
ADDITIONAL_JVM_ARGS=-Djavax.net.ssl.trustStore="c:\your_path\jssecacerts"
6. Restart Omniscope
Note 1: You will get this error if you miss step 5 or the path to 'jssecacerts' is wrong:
java.lang.RuntimeException: Unexpected error: java.security.InvalidAlgorithmParameterException: the trustAnchors parameter must be non-empty
Note 2: If -Djavax.net.ssl.trustStore="c:\your_path\jssecacerts" points to a directory instead of a file or to a non-existent path, all SSL connections will fail (regardless whether the certificates have been authorised by the most trusted authorities, SSL connections will NOT work at all) and the same error will be displayed:
java.lang.RuntimeException: Unexpected error: java.security.InvalidAlgorithmParameterException: the trustAnchors parameter must be non-empty
Note 3: There can be only one path set to -Djavax.net.ssl.trustStore="c:\your_path\jssecacerts". If you need more than one trust stores, you need to merge them into a single file and set that file to javax.net.ssl.trustStore property. If this is the case, the simplest solution is to use steps 1-3 mentioned above to add each individual URL. Each entry will be appended to the same jssecacerts file.
]]>
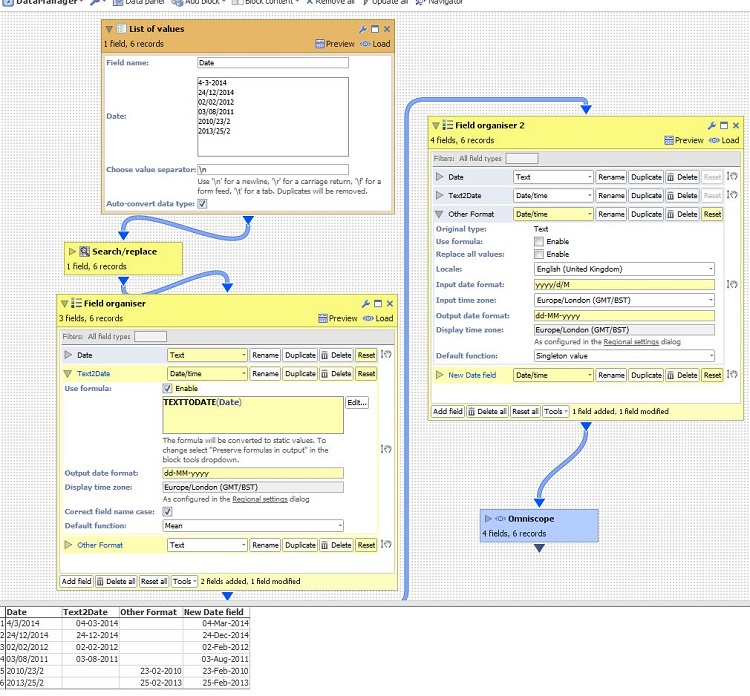
Another useful example :
4/18/2015 1:31:09.000000 AM
translates into Omniscope format
M/d/yyyy h:mm:ss.SSS a]]>
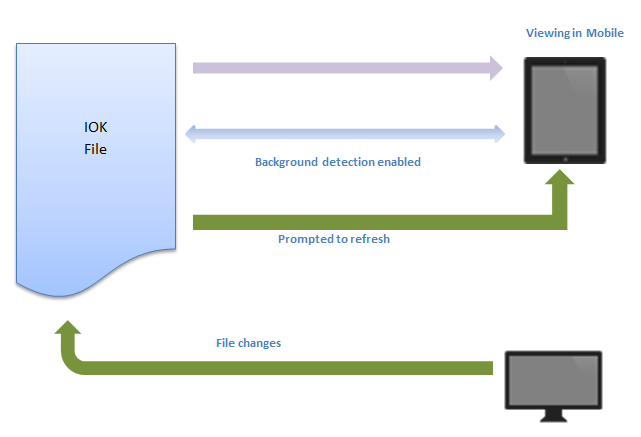
Depending on the kind of change, the client may be able to continue interacting, or be forced to reload (refresh the browser). Changes that force a reload include adding/deleting records/fields. Changes that don't force a reload include adding/removing views/tabs.
How to configure
This behaviour is configured per-file, from the Desktop app. Open the IOK file in Desktop, then click on
Settings > Web sharing>Edit client settings
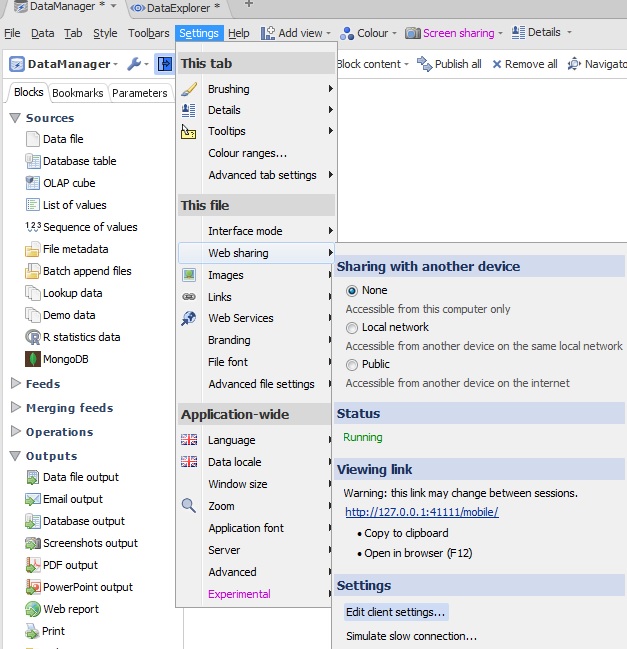
You will then be prompted with different settings you can persist in the IOK regarding Mobile. Click Edit alongside Client-side auto-refresh.
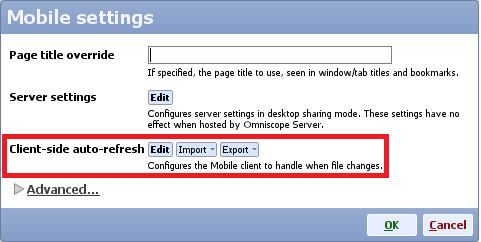
You'll see this dialog, currently showing the defaults:
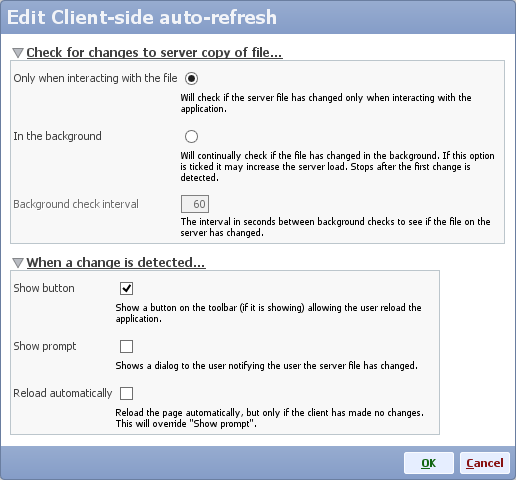
Section: Check for changes to server copy of file...
This section defines when the file on the server is checked to see if it has changed.
- Only when interacting with the file
The check will happen only when the user is actively interacting with the file e.g. when switching tabs or adjusting filters. - In the background
The check will happen periodically, in the background, while the client has the page open.
Note: this option may increase server load because the file would remain in server memory. For large files on shared servers this would prevent inactive apps from being unloaded from server memory, ultimately reducing performance in extreme cases.
Section: When a change is detected...
This section defines what happens when the client detects the file on the server has changed.
- Show button
If ticked, a lighting flash icon will appear on the main toolbar of the client (if the toolbar is showing). Clicking it will reload the application. - Show prompt
If ticked, a prompt will be shown explaining what has happened. Depending on the change, the user could choose to continue working on the session. - Reload automatically
If ticked, the client will automatically reload immediately to show the new changes, but only if the user has not made any client-side changes of their own such as filtering, selection or view menus.
You should tick this option for a live-updating dashboard.
 ]]>
]]>TYPEOF(value(left([my_string], 1)))
This returns the type of the argument passed to it (e.g. text, decimal, integer)
]]>
In the text below:
1) Change YOUR_ACCOUNT_NAME for you correspondent account name.
2.1) If you have User specific installation (not system-wide) replace OMNISCOPE_INSTALL_DIR for:
C:\Users\YOUR_ACCOUNT_NAME\AppData\Local\Visokio Omniscope app
2.1) If you have system wide installation, replace OMNISCOPE_INSTALL_DIR for:
C:\Program Files (x86)\Visokio Omniscope
Make sure that the path exists.
==========================================================
1) In your service directory
"OMNISCOPE_INSTALL_DIR\service\"
Create 2..N folders s1..sN
2) In each directory create config.xml file
and set different/correspondent port and configurationFilePath:
E.g.:
OMNISCOPE_INSTALL_DIR\service\s1\config.xml
<?xml version="1.0" encoding="UTF-8"?>
<schedulerConfig configurationFilePath="OMNISCOPE_INSTALL_DIR\service\s1\config.xml" port="24680" forkScheduledExecution="false" logDebug="false" logDetail="false" watchFolder="watch" watchPollingInterval="40">
<tasks>
</tasks>
</schedulerConfig>
OMNISCOPE_INSTALL_DIR\service\s2\config.xml
<?xml version="1.0" encoding="UTF-8"?>
<schedulerConfig configurationFilePath="OMNISCOPE_INSTALL_DIR\service\s2\config.xml" port="24682" forkScheduledExecution="false" logDebug="false" logDetail="false" watchFolder="watch" watchPollingInterval="40">
<tasks>
</tasks>
</schedulerConfig>
3) Go to "OMNISCOPE_INSTALL_DIR"
and create executable file run_scheduler.bat (if you have x64 version, leave it as in the example below otherwise change for x86 )
For Omniscope 2.7
set CONF_DIR=%1
"OMNISCOPE_INSTALL_DIR\x64\bin\java.exe" -Dsun.java2d.d3d=false -DschedulerConfigLocation="OMNISCOPE_INSTALL_DIR\service\%CONF_DIR%\config.xml" -Xms64M -XX:MaxPermSize=128M -XX:MinHeapFreeRatio=20 -XX:MaxHeapFreeRatio=30 -XX:NewRatio=8 -XX:+UseSerialGC -Xmx6183M -Dvisokio.localappdata="C:\Users\YOUR_ACCOUNT_NAME\AppData\Local" -Dvisokio.winproxyenable="0" -Dvisokio.winproxyserver="" -cp "OMNISCOPE_INSTALL_DIR\Main.jar;OMNISCOPE_INSTALL_DIR\lib\mail.jar;OMNISCOPE_INSTALL_DIR\lib\activation.jar;OMNISCOPE_INSTALL_DIR\plugins\bccrypto.jar" com.visokio.ent.EntLaunch -scheduler
From Omniscope 2.8
set CONF_DIR=%1
"OMNISCOPE_INSTALL_DIR\x64\bin\java.exe" -Dsun.java2d.d3d=false -DschedulerConfigLocation="OMNISCOPE_INSTALL_DIR\service\%CONF_DIR%\config.xml" -Xms64M -XX:MaxPermSize=128M -XX:MinHeapFreeRatio=20 -XX:MaxHeapFreeRatio=30 -XX:NewRatio=8 -XX:+UseSerialGC -Xmx6183M -Dvisokio.localappdata="C:\Users\YOUR_ACCOUNT_NAME\AppData\Local" -Dvisokio.winproxyenable="0" -Dvisokio.winproxyserver="" -cp "OMNISCOPE_INSTALL_DIR\Main.jar;OMNISCOPE_INSTALL_DIR\lib\mailapi.jar;OMNISCOPE_INSTALL_DIR\lib\smtp.jar;OMNISCOPE_INSTALL_DIR\lib\pop3.jar;OMNISCOPE_INSTALL_DIR\lib\imap.jar;OMNISCOPE_INSTALL_DIR\lib\dsn.jar;OMNISCOPE_INSTALL_DIR\lib\activation.jar;OMNISCOPE_INSTALL_DIR\plugins\bccrypto.jar" com.visokio.ent.EntLaunch -server
From Omniscope 3.0
set CONF_DIR=%1
"OMNISCOPE_INSTALL_DIR\OmniscopeEnterprise.exe" "/jvmarg=-DschedulerConfigLocation=OMNISCOPE_INSTALL_DIR\service\%CONF_DIR%\config.xml"
4) Start schedulers using run_scheduler.bat and passing folder names s1, s2, ... sN as a parameter:
E.g.:
run_scheduler.bat s1
run_scheduler.bat s2
...
run_scheduler.bat sN
You can do it into two ways.
a) You can create Shortcuts. Right-click on your Desktop->New->Shortcut.
Specify the path to your run_scheduler.bat file and pass the parameter, for example on my computer it is:
"C:\Users\michael\AppData\Local\Visokio Omniscope app\run_scheduler.bat" s1
b) Alternatively you can run the command from Windows Console - cmd.exe
5) In C:\Users\YOUR_ACCOUNT_NAME\scheduler\log.txt you should see log messages from all schedulers.
You can use attached files as templates replacing (here it is text in bold) with your current file paths
and then renaming
config_xml_tempalte.txt => config.xml
run_scheduler_bat_template.txt => run_scheduler.bat]]>
Power Tip 1) Aggregate rankings
I've got a file with the basic structure as follows:
[Name] [Value] and a whole lot of other fields
Aggregated rankings can be calculated as per this discussion (http://forums.visokio.com/discussion/comment/7339/). However, I wanted something that would display these rankings on non-aggregated data, as well as driving formulas for 'Top 10' and 'Top 100' categories (in this example, one of the KPIs is spend with top 100 Names).
To do this, I implemented the following workflow
Split off data
Delete excess fields (i.e. all but name / value)
Aggregate by Name
Rank by value (do not preserve formulas in output)
Merge rankings back into the original data
A screenshot of this is attached
Power Tip 2) Copying values from above
We have a dataset with the format
[Site]
A
null
null
B
null
null
i.e. a field that is only populated for the first row of each section of data.
There is some discussion of how to copy these values down into the null cells here (http://forums.visokio.com/discussion/comment/8577/#Comment_8577) but I'm not familiar with these scripts and so didn't want to use them.
Instead, I created some new formula fields as follows:
[Linenumber] = currentrow()
[Linenumber Site] = if([Site]=null, null, currentrow())
[Site updated] = CELL([Site], SUBSET_MAX([Linenumber Site], SUBSET([Linenumber], CURRENTROW(), "<=")))<br />
This creates a new field [Site updated] with the values copied down. With the current dataset (19 fields, 10k records) these forumlas run pretty much instantly.
If you wanted to get sneaky, you could then rename [Site updated] to [Site] and delete the added fields. This would eliminate the calculations from the final file.
]]>
Following formula in the FieldOrganiser helps populate empty fields with the single value, for the given combination of 3 fields, where field [Provider Tax ID] is only partially populated.
SUBSET_FIRSTNONNULL([Provider Tax ID],
SUBSET3([Provider Fname], [LnameCorrected], [AddressCorrected]))]]>What I would like to be able to do is to work out the total per charterer in the last 52 weeks.
I have created a field called [islast52] that gives me a 'y' or 'n' depending. Then I am trying the following to get the results. However, I cant quite get it right. Some help would be great.
SUBSET_SUM([Total USD Fixture], SUBSET([Charterer.fixture]),
subset([IsLast52.fixture],"y","=")))
Thanks, Dave
]]>
Open the existing file, and from
Tab > New select Copy of current tab (advanced)
You will be given the option to set this new version of the tab to use the filtering settings on previous tabs by un-ticking ‘Filter states’
]]>
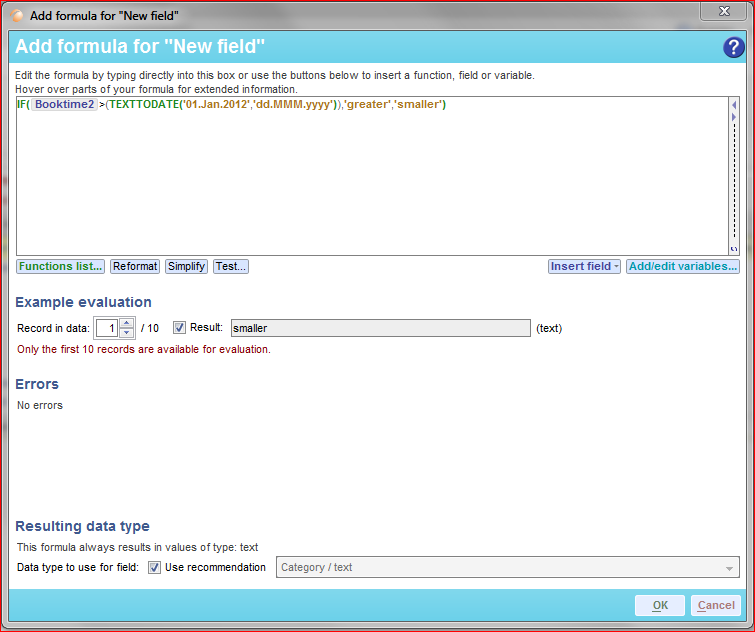 ]]>
]]> ]]>
]]>Company Name | Date | Daily Sales
ABC | 22/03/2013 | 22
ABC | 22/03/ 2013 | 23
ABC | 23/03/ 2013 | 40
ABC | 23/03/ 2013 | 50
DEF | 22/03/2013 | 10
DEF | 22/03/2013 | 20
DEF | 23/03/2013 | 30
DEF | 23/03/2013 | 60
In Omniscope, I have aggregated by Company Name & Date which gives me:
Company Name | Date | Daily Sales
ABC | 22/03/2013 | 45
ABC | 23/03/2013 | 90
DEF | 22/03/2013 | 30
DEF | 23/03/2013 | 90
My next step is to calculate cumulative sales by company name & date. So I want my outcome to be:
Company Name | Date | Daily Sales | Cumulative Sale
ABC | 22/03/2013 | 45 | 45
ABC | 23/03/2013 | 90 | 135
DEF | 22/03/2013 | 30 | 30
DEF | 23/03/2013 | 90 | 120
So how do I derive the cumulative sales?
Cheers, Firman]]>
For example, if you have turned on the Compatibility view settings in Internet Explorer, the web view will use the same settings to display the web page. See here for more detail about Compatibility view settings.
Having compatibility view turned on may result in web pages not display properly in web view.]]>
- INTERSECTION - http://www.visokio.com/functions-guide#INTERSECTION
- UNION - http://www.visokio.com/functions-guide#UNION
- INVERSE - http://www.visokio.com/functions-guide#INVERSE
These greatly improve the simplicity, flexibility and power of subsets in formulas. They replace the complicated SUBSET2, SUBSET3 (etc.) functions, and more. Instead of these, use INTERSECTION(SUBSET(...), SUBSET(...), SUBSET(...)).
Examples:
The sum of Sales for all records with a different currency to the current record:
SUBSET_SUM( Sales, INVERSE(SUBSET(Currency)) )
The number of records with yield < 0.1 and in USD or GBP:
RECORDCOUNT(INTERSECTION(
UNION(SUBSET(Currency, "USD"), SUBSET(Currency, "GBP")),
SUBSET(Yield, 0.1, "<")<br />))
See Subset Functions Guide: http://www.visokio.com/kb/subset-functions]]>
In various DataManager workflows, I use the Collapse Values operation.
Yet I am struggling with the performance of this operation. What can I do to make it faster? Is it an option to use the formula equivalent ([Field A]&"seperator"&[Field B]) or will this only be slowing down even more?
Thanks! ]]>
401 Authorization RequiredEven if the user is providing the correct authentication details, a misconfiguration of the IIS server (on which Sharepoint runs) may cause the aforementioned error.
Here follows 2 default Sharepoint/IIS configurations that you may try to apply to solve the problem:
- Sharepoint 2007 with IIS 7.0
- Go to the IIS settings , choose the Sharepoint site you need to configure, and double click on the "Authentication" icon
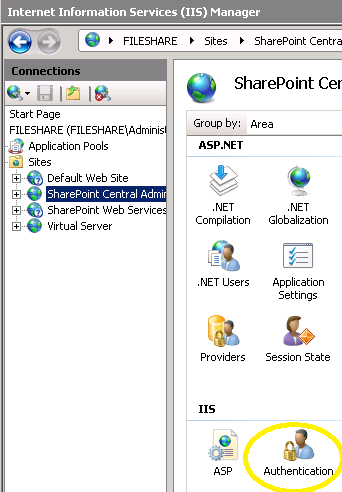
- Enable the "Windows Authentication"
- Click on "Advanced settings" and ensure "Enable Kernel-mode Authentication" option is ticked.
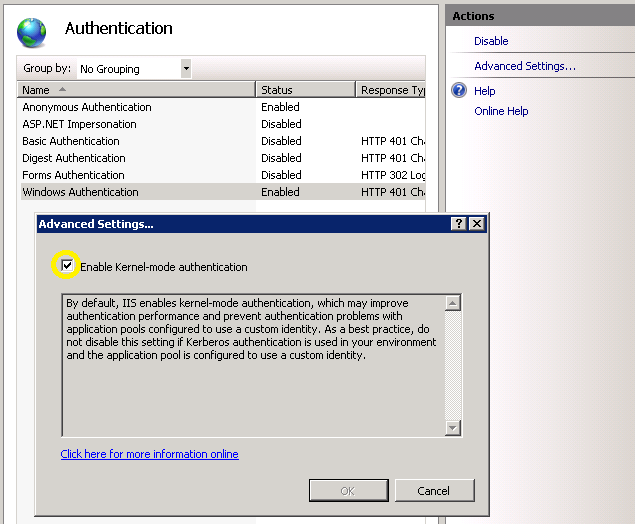
- Go to the IIS settings , choose the Sharepoint site you need to configure, and double click on the "Authentication" icon
- Sharepoint 2010 with IIS 7.5
- Go to the IIS settings , choose the Sharepoint site you need to configure, and double click on the "Authentication" icon
- Enable the "Windows Authentication"
- Click on "Providers..." and ensure that "NTLM" is in the "Enabled Providers" list
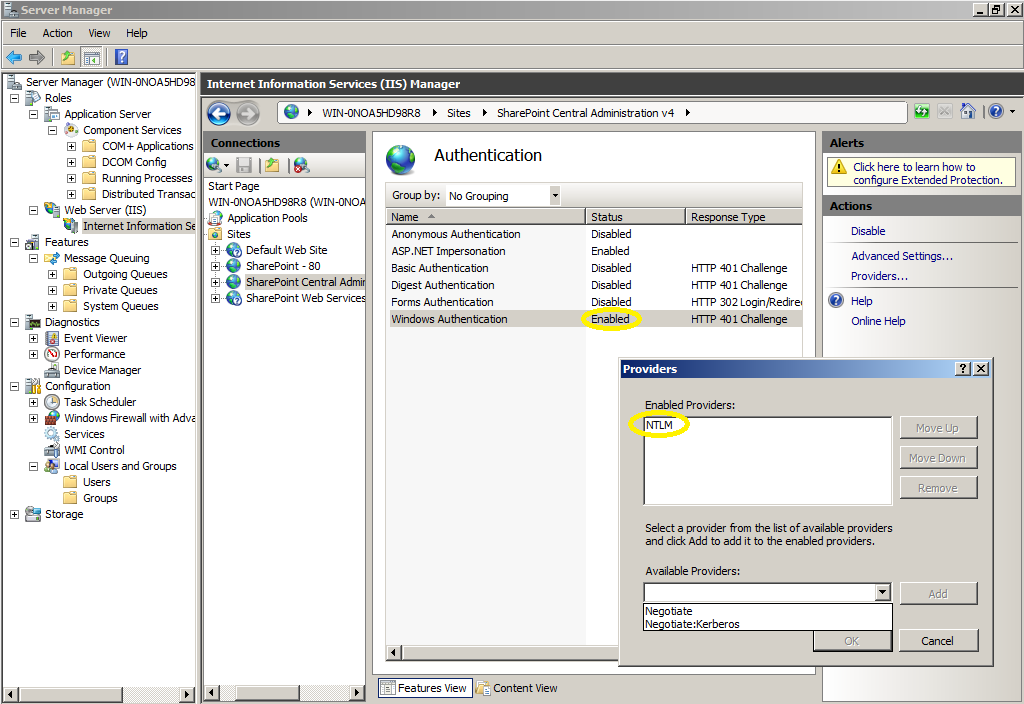
- Go to the IIS settings , choose the Sharepoint site you need to configure, and double click on the "Authentication" icon
Firstly, the use case to answer the question "Why would I want to do this?":
Omniscope users familiar with the formula language may well have come across the SEARCH and SEARCHREGEX functions, which return the position at which a particular character/phrase (in the case of SEARCH) or regular expression pattern (in the case of SEARCHREGEX). These functions are often used to extract elements of text - for example, extracting parts of a postcode; the UK postcode comprises 4 sections:
So, from a full postcode, we might want to extract the postcode area (first 1-2 characters) or the postcode district (all characters before the space). Finding the space, and extracting everything left of the space, is fairly easy using the SEARCH function, so I will focus on the trickier example of extracting the postcode area.
Using SEARCHREGEX, I can do this in Omniscope by detecting the first alpha character (i.e. A-Z) and the first numeric character (i.e. 0-9) and then extract the characters between these two extremes. To do this we would use:
DECLARE(
/* Store position of first alpha (A-Z) and first nuymeric (0-9) */
firstAZ, SEARCHREGEX("[A-Z]",[Postcode]),
first09, SEARCHREGEX("[0-9]",[Postcode]),
IF(
/* Check that we found both an alpha and a numeric, and that the numeric is after the alpha i.e. a valid postcode format */
AND(firstAZ > 0,first09 > firstAZ),
/* Extract the alpha characters, if valid */
MID([ Postcode], firstAZ, first09-firstAZ),
/* Return nothing if postcode invalid */
NULL
)
)However, regex extraction is simpler and (once we're confident in regex - lots of tutorials online) allows for far more complex extractions. So here is the same function using Javascript:
SCRIPT(`
// Declare the pattern we want to extract, and then apply it to our input text
var re = /([A-Z]*)/;
var m = re.exec(text1);
// We should have one (or more) groups of character sets now
if (m == null) {
// If not, then return "No"
'No'
} else {
// If we do have at least one character group, return the first (could return many, concatenated, if required)
m[0]
}
`, "text1", [Postcode])The structure of this is:
- Firstly we have the Javascript code itself, which includes the use of a variable called "text1"
- Then, in the last line, we have the declaration of "text1" (this can be called anything, and needs to be the same name here as inside the script itself, and passing the value of our [Postcode] field into this variable, for use in the script
This only scrapes the surface of this (Javascript regex) approach - there are many ways to use this as the basis for far more complex, and valuable, text extractions... but as Steve's original article demonstrates, there are many, many more uses for Javascript.
Happy scripting... ]]>
open -n /Applications/"Visokio Omniscope.app"
this will open another Omniscope instance and you can open a second file and work with it as normal.]]>
Any thoughts?]]>
To create deciles for a selected field ("GrossUnits" in this example, just replace with your field name):
10-INTFLOOR(RANK([GrossUnits],"GrossUnits")/(DATASET_NONEMPTYCOUNT("GrossUnits")/10))
to create quartiles instead, simply replace each 10 with 4 i.e.
4-INTFLOOR(RANK([GrossUnits],"GrossUnits")/(DATASET_NONEMPTYCOUNT("GrossUnits")/4)
Breaking this down...
1. Firstly we find out where each row ranks in the dataset, based on its GrossUnits value:
RANK([GrossUnits],"GrossUnits")
2. Then we calculate the number of rows of data which contain numeric values:
DATASET_NONEMPTYCOUNT("GrossUnits")
and then divide this by 4 or 10 (or any other integer e.g. 100 for percentiles) to calculate how many rows fit in each "band" of our grouping
3. Then we divide the rank by the position by the number of records in each band, and round down the result:
INTFLOOR(RANK([GrossUnits],"GrossUnits")/(DATASET_NONEMPTYCOUNT("GrossUnits")/4
4. Finally, we subtract the result from our grouping to get the result - the very highest value in the dataset will get a rank of 1, which when divided by the number of records in a band (more than 1), and then rounded down, will result in 0... which when subtracted from our grouping value will place it in the top band, correctly.
Note: The DATASET_NONEMPTYCOUNT function will not include rows where cells are blank (you will need to replace them with zeros to address this).]]>