Note: See also examples of commonly-used formulae [1], or consult the Functions Guide [2] for documentation of all functions available for use in formulae.
Omniscope allows you to add formula fields, which are special fields (columns) whose values are calculated and re-calculated on opening/refresh according to the defined formula using inbuilt functions. Formulae combine references to other fields, mathematical expressions, a standard set of functions similar to spreadsheets such as Excel, and additional Omniscope-specific Subset functions which operate on evaluated subsets of your overall data set. Formulae in Omniscope are written in a similar sytax to spreadsheet formulae, using an interactive, visual editor and some easy-to-use variables for defining assumptions and sensitivity ranges. Subset functions do not exist in spreadsheets and therefore have their own syntax unique to Omniscope.
Formulas are composed and edited using Omniscope's powerful Omniscope Formula editor [3] which provides error feedback, preview of partial results and function assistance. Omniscope also allows you to define additional values called Variables [4], which are input assumptions, rather than values found within the fields (columns) of the data set. Variables have a single value, but are usually presented in a device allowing the user to change the value across a configurable range (see Add/Edit variables below). Variables are used for enabling multi-variate, dynamic sensitivity analyses and real-time modelling options that can be controlled by any user of the file.
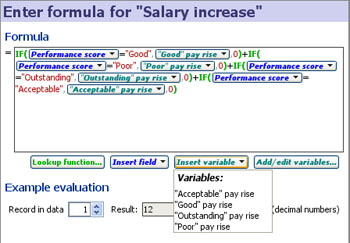
This example below shows a formula for calculating staff salary increases based on performance scores using a conditional IF statement to test a field text value and apply the corresponding Variables:
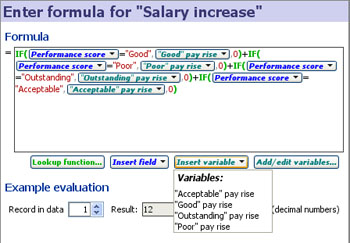 | 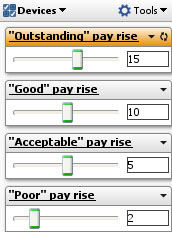 |
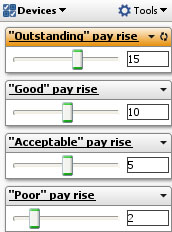
This example is taken from the embedded demo file File > Demos > Human resources, tab: Salary cost analysis. The data includes a column called 'Performance score' with 4 values; '"Acceptable", "Good", "Outstanding" and "Poor". The formula above uses nested IF functions (in green) and compares the value in the field'Performance score' (in blue), with typed in test values (enclosed in double quotes) reflecting the names of the Variables already defined, such as "Good" (in red). If the values match, i.e. an employee's value in the 'Performance score' column is "Good", then they will receive the pay rise defined by the Variable 'Good Pay rise'(since all the other IF comparisons will fail and the other parts of the expression will be zero). The Variable 'Good pay rise' has a default value (10) and a range. Each Variable defined also has an associated Side Bar device. If you reveal the Variables on the Side Bar, users of the file can perform real-time modelling and sensitivity analysis just by changing the assumed values using the sliders (see above right).
Unlike formulae in spreadsheets based on individual cell references, Omniscope formulae only contain field references, which are equivalent to saying "the cell in column X in the same row". You cannot define an Omniscope formula that depends on the value in a cell belonging to another record (row).
Formula fields can be added and defined using the Formula Editor accessible from the Main Toolbar using Data > Formulas and also from within the Table View using the Formulas button.
Use Data > Formulas > Add formula field to create a new field whose values calculated using a formula. You will be prompted to enter the name of the new field, before seeing the Formula editor [3] which you use to edit your formula.
 |  |
To edit an existing formula, choose Data > Formulas > Edit formula. You will first be prompted to choose the formula field.
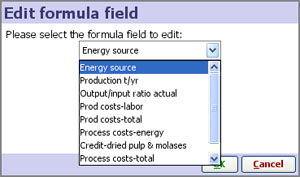
Alternatively, use the field menu to edit the formula for a given field. Field menus can be found by right-clicking the Table View column header, right-clicking the Sidebar filter device title, or through the Data> Manage Fields [5] window. The Formula Editor [3] will open showing your existing formula which can be edited as text.
If you already have a blank field with the correct name, right-click the column header in the Table View, or use the Edit option in Data > Manage fields [5]. From the menu, choose Change to formula field. Alternatively, use Data > Formulas > Convert existing field to use formula. If the field already has data in its cells, you will be warned, as these values will be replaced with the formula results. The Formula Editor [3] will open allowing you to enter the formula.
Variables [4] are values with ranges you define which are not contained in the data set, but are available to be used in Formula field calculations. Variables [4] can take on a range of values, and if you reveal the corresponding Side Bar device, you and users of your files can 'use Side Bar sliders a check-boxes to 'flex' the model assumptions, performing real-time, multi-variate simulations and sensitivity analysis, with all views and totals updating automatically. For more detail on defining, manipulating and using variables in formulas, see Defining Variables [4].
Omniscope automatically recalculates all formulas where necessary when any of their dependencies change. If you edit a value in a field, any formulas that refer to it will recalculate for the same record. Formulas that refer to the sum of the entire field will recalculate for all records. If you adjust a Variable, any formulas that refer to it will recalculate for all records. In short, Omniscope takes care of ensuring your formulas and data are always consistent.
Formulas that change over time (for example, those that use the RAND() function) are recalculated when you open the file. You can tell Omniscope to recalculate all your formulas by using Data > Formulas > Recalculate all values. Or, to recalculate a single field, use Data > Manage fields [5] > Edit > Recalculate values.
If you are working on a large and complex model, you may wish to disable automatic recalculation of formulas by deselecting Data > Formulas > Calculate automatically. This will make Omniscope perform faster when adding and deleting fields, for example. Be warned that any edits to formulas will not be recalculated until you manually use Recalculate [all] values. Any formula fields you add will appear blank until you trigger recalculation.
You can remove the formula for fields while retaining their data as static values using Data > Manage fields [5] > Edit > Change to static values (for a single field) or Data > Formulas > Convert all formulas to static values. The data will be unchanged, but will no longer be recalculated when you change variables or update your data. You can restore the formula by changing back to a formula field (see above).
If you want to remove the underlying formula altogether from the file, perhaps to keep your trade secrets, use the Convert and erase option in the dialog shown when converting to static values. Alternatively, in the File > Save as dialog, tick Convert formulas to static values to export a file with all formulas removed and erased, with only the formula results as static data.
Sometimes a formula can appear to be written correctly but may fail when evaluating certain records. One example is where you are dividing by a field in one of you formulas, and that field contains a zero.
When this happens, the Table view's Formula button will be highlighted in red/pink, and on clicking it, View last formula error will appear in the menu. Choose this item to open the formula editor for the field with the problem. The Example evaluation > Record in data spinner will be preconfigured to show the record with the problem, and the Errors section will show the error for that record.
It can also be useful to find out what fields a formula references, and conversely, what formulas a field is used in. Hover over a field anywhere in the application (such as in Data > Manage Fields [5]) to see a summary of that field's "References" (if it is a formula field) and "Referenced by" (if it is referenced by other formulas).
This section expands on the Formula Editior Omniscope documentation of functions available for use in formula fields to calculate values based on values in other columns. Most of the functions/syntax are the same as those used in spreadsheets like Excel, but there are also powerful Omniscope-specific SUBSET functions that perform operations on evaluated data subsets, both aggregated and disaggregated.
See also: Useful formulae [6] Guide to SUBSET functions [7] Deprecated functions [8] Additional functions in Javascript [9] Explore this list in Omniscope [10]
Function | Usage | Description |
| ABS | ABS(number) | Returns the absolute value of a number, a number without its sign. |
| ACOS | ACOS(number) | Returns the arccosine of a number, in radians in the range 0 to Pi. The arccosine is the angle whose cosine is Number. |
| ACOSH | ACOSH(number) | Returns the inverse hyberbolic cosine of a number. |
| ALLRECORDCOUNT (Omniscope 2.6+) |
ALLRECORDCOUNT() | Evaluates to the total number of records (rows) in all data, before any filtering or in-view aggregation has been applied. Not supported for dynamic evaluation in aggregated views. |
| AND | AND(logical1, logical2, ...) | Checks whether all arguments are TRUE, and returns TRUE if all arguments are TRUE. |
| ASIN | ASIN(number) | Returns the arcsine of a number in radians, in the range -Pi/2 to Pi/2. |
| ASINH | ASINH(number) | Returns the inverse hyperbolic sine of a number. |
| ATAN | ATAN(number) | Returns the arctangent of a number in radians, in the range -Pi/2 to Pi/2. |
| ATANH | ATANH(number) | Returns the inverse hyperbolic tangent of a number. |
| AVG | AVG(value1, value1, ...) | Returns the average (arithmetic mean) of its arguments. |
| BUCKET (Omniscope 2.6+) |
BUCKET(value, width, number_format_or_date_unit, date_format) In scripts: bucket(value, width, number_format_or_date_unit, date_format) |
Retrieves a range for a date or a number as a text value in the format "A to B". For numbers, use BUCKET(value, width, format); for dates use BUCKET(value, width, unit, format). In either case, "format" is optional. Date units can be one of: "year", "month", "week", "day", "hour", "minute", "second", "millisecond". Numeric examples: BUCKET(5, 10) = '0 to 10' BUCKET(0.08, 0.1) = '0 to 0.1' BUCKET(0.1, 0.1) = '0.1 to 0.2' BUCKET(0, 0.1) = '0 to 0.1' BUCKET(0.11, 0.1) = '0.1 to 0.2' BUCKET(1002, 10) = '1000 to 1010' BUCKET(10000, 11) = '9999 to 10010' Date examples where field1 is 10 Feb 2007 12:43: BUCKET([field1], 2, "hours") = '10 Feb 2007 12:00 to 10 Feb 2007 14:00' BUCKET([field1], 2, "hours", "HH:mm") = '12:00 to 14:00' BUCKET([field1], 2, "months", "dd MMM yyyy") = '01 Jan 2007 to 01 Mar 2007' BUCKET([field1], 2, "years", "dd MMM yyyy") = '01 Jan 2006 to 01 Mar 2008' BUCKET([field1], 12, "seconds", "HH:mm ss") = '12:43 00 to 12:43 12' |
| CATCH (Omniscope 2.7+) |
CATCH(sub_formula) | Suppresses all evaluation errors in the sub-formula. If an error occurs, results in null. |
| CELL (Omniscope 2.8+) |
CELL(field, record) In scripts: cell(field, record) |
Retrieves a cell value for a field using an absolute row number. The field must be a field name; see also FIELDNAME and FIELDCOUNT functions. |
| CHOOSE | CHOOSE(index_num, value1, value2, ...) | Chooses a value from a list of values, based on an index number (beginning at 1). |
| COMBIN | COMBIN(number, number_chosen) | Returns the number of combinations for a given number of items. |
| CONTAINS (Omniscope 2.6+) |
CONTAINS(text, sub_text) | Returns true if [sub_text] occurs anywhere within [text] (case insensitive). |
| CONVERT_LATLON_TO_OSGBX (Omniscope 2.7+) |
CONVERT_LATLON_TO_OSGBX(lat, lon) | Converts coordinates from the latitude value in WGS 84 (GPS lat/lon) to British National Grid (OSGB 36) X. |
| CONVERT_LATLON_TO_OSGBY (Omniscope 2.7+) |
CONVERT_LATLON_TO_OSGBY(lat, lon) | Converts coordinates from the latitude value in WGS 84 (GPS lat/lon) to British National Grid (OSGB 36) Y. |
| CONVERT_OSGB_TO_LAT (Omniscope 2.5+) |
CONVERT_OSGB_TO_LAT(osgbX, osgbY) | Converts coordinates from British National Grid (OSGB 36) to the latitude value in WGS 84 (GPS lat/lon). |
| CONVERT_OSGB_TO_LON (Omniscope 2.5+) |
CONVERT_OSGB_TO_LON(osgbX, osgbY) | Converts coordinates from British National Grid (OSGB 36) to the longitude value in WGS 84 (GPS lat/lon). |
| COS | COS(number) | Returns the cosine of an angle. |
| COSH | COSH(number) | Returns the hyperbolic cosine of a number. |
| CURRENTROW | CURRENTROW() | Evaluates to the row number of the record being evaluated. Numbering starts at 1. |
| DATE (Omniscope 2.7+) |
DATE(year, month, day, hour, minute, second, millisecond, timezone) In scripts: date(year, month, day, hour, minute, second, millisecond, timezone) |
Creates a date using numerical arguments. If omitted or null, the first value for each arguments is used. So, if year is null, year 1 is used. If month is null or omitted, January is used. Etc. BC dates are not supported. Illegal dates such as day 29 Feb on a non-leap year will be rolled over. Time zone is a text value in the format "GMT-8:00" or "PST"; if omitted, the local time zone is used. |
| DATEADD (Omniscope 2.5+) |
DATEADD(date, number, unit) In scripts: dateAdd(date, number, unit) |
Adds a specified number of a specified unit to a date. To subtract, use a negative number. Unit is optional; if not specified, "day" is assumed, otherwise it should be specified as: "year", "month", "week", "day", "hour", "minute", "second", "millisecond". |
| DATEDIFF | DATEDIFF(date1, date2, unit, approximate) In scripts: dateDiff(date1, date2, unit, approximate) |
Establishes the difference between two dates, as a decimal number of a specified unit (optional, default: "day"). If date2 is before date1, the result will be negative. E.g. the decimal number of weeks between two dates. Units should be specified as: "year", "month", "week", "day", "hour", "minute", "second", "millisecond". You can optionally choose approximate date difference for faster value calculation by specifying "true" for "approximate". Approximate date difference divides elapsed time between the two dates by the typical unit length (e.g. 30 days for days-in-month). |
| DATETOTEXT (Omniscope 2.6+ (for time zone argument)) |
DATETOTEXT(date_value, custom_format, time_zone) In scripts: dateToText(date_value, custom_format, time_zone) |
Converts a Date into text, optionally using a custom date format and time zone. For more information please click here [11]. |
| DATEUNIT (Omniscope 2.5+) |
DATEUNIT(date, unit) In scripts: dateUnit(date, unit) |
Retrieves a specified unit from a date as a numeric value. For example, the date "12 Feb 2006" has 12 as the "day" unit. Unit is optional; if not specified, "day" is assumed, otherwise it should be specified as: "year", "month", "week", "day", "hour", "minute", "second", "millisecond". NB. "days" is interpreted as "day of month", "weeks" as "week of year", and "hours" as "hour of day (24)". |
| DATEVALUE | DATEVALUE(text) | Converts a text string that represents a date to a date. For more options, see TEXTTODATE. |
| DECLARE (Omniscope 2.6+) |
DECLARE(name1, expression1, name2, expression2, name3, expression3..., sub_formula) | Declares one or more named values, each with a value expression, for repeated use in a sub-formula. The names must not clash with existing field or variable names, and must not be quoted. For more information, see DECLARE function [12]. |
| DEPENDENCIES (Omniscope 2.7 b414+) |
DEPENDENCIES(nested_formula, ref1, ref2, ref3...) | Provides a hint to Omniscope that the nested formula has references to other fields. Use this when you are building up field references in ways that Omniscope cannot automatically determine, such as via the SCRIPT function. Omniscope needs to know about all field references in a formula to ensure correct evaluation. Example: DEPENDENCIES(SCRIPT(` ... dataArray("MyField") ... refVal("MyOtherField") ... `), [MyField], [MyOtherField]) This tells Omniscope that the script has references to MyField and MyOtherField. |
| E | E() | Euler's number, e, also called the base of natural logarithms. |
| ENDSWITH (Omniscope 2.6+) |
ENDSWITH(text, sub_text) | Returns true if [sub_text] occurs in the end of [text] (case insensitive). |
| EQUIV (Omniscope 2.6+) |
EQUIV(value1, value2) | Returns true if [value1] is equivalent to [value2] (automatically converting between text, numbers and dates to attempt to find a match). |
| EXP | EXP(number) | Returns e raised to the power of a given number. |
| FACT | FACT(number) | Returns the factorial of a number, equal to 1*2*3*...*Number. |
| FIELDCOUNT (Omniscope 2.8+) |
FIELDCOUNT() In scripts: fieldCount() |
Returns the number of fields present. |
| FIELDFORMAT | FIELDFORMAT(value, field) | Converts any value into the text equivalent, using a field format. Warning: boolean values (true/false) will be translated using the current Language setting. Usage examples: FIELDFORMAT(424, [Field 1]) = "424.00" |
| FIELDNAME (Omniscope 2.8+) |
FIELDNAME(field_number) In scripts: fieldName(field_number) |
Looks up a field name by number, e.g. the 5th field. |
| FIELDNUMBER (Omniscope 2.8+) |
FIELDNUMBER(field_name) In scripts: fieldNumber(field_name) |
Looks up a field number by name (reverse of FIELDNAME). |
| FINDBETWEEN (Omniscope 2.7+) |
FINDBETWEEN(all, before, after) | Returns the first shortest matching text surrounded by [before] and [after], or null if not found. For example, FINDBETWEEN("apple apple orange plum pear apple banana pear", "apple", "pear") would return " orange plum " |
| FINDLASTBETWEEN (Omniscope 2.7+) |
FINDLASTBETWEEN(all, before, after) | Returns the last shortest matching text surrounded by [before] and [after], or null if not found. For example, FINDLASTBETWEEN("apple apple orange plum pear apple banana pear", "apple", "pear") would return " banana " |
| HTTPREDIRECT | HTTPREDIRECT(url) | Retrieves the HTTP redirect target for a URL, if the server provides one. |
| IF (Use of extended form requires Omniscope 2.5+) |
IF(logical_test, value_if_true, value_if_false) or IF(test1, value1, test2, value2, test3, value3..., else_value) | Checks whether a condition is met, and returns one value if TRUE, and another value if FALSE If the longer form is used, returns value1 if test1 is true, otherwise returns value2 if test2 is true, otherwise returns value3 if test3 is true..., otherwise returns else_value. For example: IF( [Coupon]<6, "less than 6", [Coupon]<7, "6 to 7", [Coupon]<8, "7 to 8", "8+" ) |
| INTCEIL | INTCEIL(number) | Rounds a number up to the nearest integer. |
| INTERSECTION (Omniscope 2.6+) |
INTERSECTION(subset1, subset2, ...) In scripts: intersection(subset1, subset2, ...) |
Returns the data subset which is the intersection of records for all data subset arguments. If a record is present in ALL supplied subsets, it will be present in the result. WARNING: this is an experimental function that has not been optimised for performance. Use alternative solutions such as extra formulas and the SUBSET function if performance is unacceptable. For more information, please visit SUBSET functions [7]. |
| INTFLOOR | INTFLOOR(number) | Rounds a number down to the nearest integer. |
| INTROUND | INTROUND(number) | Rounds a number to the nearest integer. |
| INVERSE (Omniscope 2.6+) |
INVERSE(subset) In scripts: inverse(subset) |
Inverts the set of included records of a data subset. All records included in the subset supplied will be excluded in the result, and vice versa. WARNING: this is an experimental function that has not been optimised for performance. Use alternative solutions such as extra formulas and the SUBSET function if performance is unacceptable. For more information, please visit SUBSET functions [7]. |
| ISO_COUNTRY_NAME (Omniscope 2.5+) |
ISO_COUNTRY_NAME(code, display_language) | Converts an ISO country code into readable form. The function uses two arguments: code. The ISO language code. This can be either a 2-letter code language code or a 3-letter code. display_language. Optional argument. The language of the function text result. This can be either a 2-letter code language code or a 3-letter code. |
| ISO_LANGUAGE_NAME (Omniscope 2.5+) |
ISO_LANGUAGE_NAME(code, show_country, display_language) | Converts an ISO language code into readable form. The function uses three arguments: code. The ISO language code. This can be either a 2-letter code language code, 2-letter language/country code or a 3-letter code. show_country. Optional argument. If this is set to true and a 2-letter language/country code is provided the country will be shown in brackets after the language. The default value is true. display_language. Optional argument. The language of the function text result. This can be either a 2-letter code language code or a 3-letter code. |
| LASTDAYOFMONTH (Omniscope 2.6+) |
LASTDAYOFMONTH(date_value) | Returns last day of month for a given date. Date value should include month and year value. |
| LAT_LON_DISTANCE (Omniscope 2.7+) |
LAT_LON_DISTANCE(lat1, lon1, lat2, lon2) | Returns the surface distance (in KM) from one latitude/longitude point to another. |
| LEFT | LEFT(text, num_chars) | Returns the specified number of characters from the start of a text string. |
| LEN | LEN(text) | Returns the number of characters in a text string. |
| LEVENSHTEIN (Omniscope 2.8+) |
LEVENSHTEIN(value1, value2) In scripts: levenshtein(value1, value2) |
Evaluates the Levenshtein distance [13] between two text values (case insensitive). |
| LG | LG(number) | Returns the base-2 logarithm of a number. |
| LN | LN(number) | Returns the natural logarithm of a number. |
| LOG | LOG(number, base) | Returns the logarithm of a number to the base you specify. |
| LOWER | LOWER(text) | Converts all letters in a text string to lowercase. |
| MAX | MAX(value1, value1, ...) | Returns the largest value in a set of values. |
| MID | MID(text, start_num, num_chars) | Returns the specified number of characters from the middle of a text string, given a starting position and length. |
| MIN | MIN(value1, value1, ...) | Returns the smallest number in a set of values. |
| MOD | MOD(number, divisor) | Returns the remainder after a number is divided by a divisor. |
| NORMDIST (Omniscope 2.8+) |
NORMDIST(x, mean, sdev, cumulative) In scripts: normDist(x, mean, sdev, cumulative) |
Gives the probability that a number falls at or below a given value of a normal distribution. X - is the value for which you want the distribution, mean (by default 0) - is the arithmetic mean of the distribution, sdev (by default 1) - is the standard deviation of the distribution, the value should be positive (>0) cumulative (by default TRUE) - is a logical value that determines the form of the function. If cumulative is TRUE, NORMDIST returns the cumulative distribution function; if FALSE, it returns the probability mass function. See also NORMSDIST: NORMDIST(x,mu,sigma,TRUE) = NORMSDIST((x - mu)/sigma). |
| NORMINV (Omniscope 2.8+) |
NORMINV(probability, mean, sdev) In scripts: normInv(probability, mean, sdev) |
It is the inverse of the NORMDIST function. It calculates the x variable given a probability. probability - is a probability corresponding to the normal distribution, the value should be in the range (0, 1), >0 and <1, mean (by default 0) - is the arithmetic mean of the distribution, sdev (by default 1) - is the standard deviation of the distribution, the value should be positive (>0). |
| NORMSDIST (Omniscope 2.8+) |
NORMSDIST(x, cumulative) In scripts: normSDist(x, cumulative) |
Gives the probability that a number falls at or below a given value of a standard normal distribution. X - is the value for which you want the distribution, cumulative (by default TRUE) - is a logical value that determines the form of the function. If cumulative is TRUE, NORMSDIST returns the cumulative distribution function; if FALSE, it returns the probability mass function. See also NORMDIST: NORMDIST(x,mu,sigma,TRUE) = NORMSDIST((x - mu)/sigma). |
| NORMSINV (Omniscope 2.8+) |
NORMSINV(probability) In scripts: normSInv(probability) |
It is the inverse of the NORMSDIST function. It calculates the x variable given a probability. probability - is a probability corresponding to the normal distribution, the value should be in the range (0, 1), >0 and <1. |
| NOT | NOT(logical) | Changes FALSE to TRUE, or TRUE to FALSE. |
| NOW | NOW() | Returns the current date/time. |
| NUM_OF_TOKENS | NUM_OF_TOKENS(text, token_separator) | Returns the number of tokens (split by a single character such as a comma) in a text value. |
| NUMVALUE | NUMVALUE(text) | Converts a text string that represents a number to a number. |
| OR | OR(logical1, logical2, ...) | Checks whether any arguments are TRUE, and returns TRUE or FALSE. Returns FALSE only if all arguments are FALSE. |
| PI | PI() | Returns the value of Pi, 3.141592653589793, accurate to over 15 digits. |
| POWER | POWER(number, power) | Returns the result of a number raised to a power. |
| PROPER | PROPER(text) | Converts a text string to proper case; the first letter in each word in uppercase, and all other letters to lowercase. |
| RAND | RAND() or RAND(seed) | Returns a random number greater than or equal to 0 and less than 1, evenly distributed. The result changes on every recalculation, unless a seed value (any number) is specified, in which case the number generated is always the same for a given seed. |
| RANK (Use of dataSubset argument requires Omniscope 2.5+) |
RANK(value, field, isAscending, includeNulls, dataSubset) | Returns the rank of a value within the field specified. This is the value position within the array of ordered field values. If isAscending parameter is not specified, FALSE or takes string "descending", the rank is against a descending order (higher values give better rank, with the highest number giving rank 1). If isAscending parameter is TRUE or takes string "ascending", the rank is against an ascending order. If the value is NULL, or not present in the list, NULL is returned, unless includeNulls is specified as true, in which case empty cells in the list will be considered. If dataSubset is specified, the RANK is calculated for a subset of the data which can be specified using the SUBSET function. Examples: RANK(10.1, [field1]) RANK(10.1, [field1], 1) RANK(10.1, [field1], true) RANK(10.1, [field1], "ascending") Valid argument combinations without data subset: RANK(field) (shorthand for RANK(field, field)) RANK(value, field) RANK(value, field, isAscending) RANK(value, field, isAscending, includeNulls) Valid argument combinations with data subset: RANK(value, field, dataSubset) RANK(value, field, isAscending, dataSubset) RANK(value, field, isAscending, includeNulls, dataSubset) For more information, please visit SUBSET functions [7]. |
| READRES | READRES(file_path_or_url, max_cache_age_seconds) | Reads the text contents from a file or URL. If the maximum cache age in seconds is not specified, it will be assumed to be 1 minute. Downloaded data will be cached for this period. Use -1 to disable caching. |
| RECORDCOUNT (Omniscope 2.5+) |
RECORDCOUNT(subset) In scripts: recordCount(subset) |
Evaluates to the number of records (rows) in the all data (if subset is not specified), or a subset (if subset is specified). The subset should be a data subset as evaluated using the SUBSET function. |
| REFVAL (Omniscope 2.6+) |
REFVAL(field_name) In scripts: refVal(field_name) |
Looks up the value of a field or variable by its name. The name can be dynamically determined, such as by concatenating text and/or using variables. |
| REPLACE | REPLACE(old_text, start_num, num_chars, new_text) | Replaces part of a text string with a different text string. |
| REPLACEREGEX (Omniscope 2.6+) |
REPLACEREGEX(text, regular_expression, replace_text, use_empty_if_no_match) | Replaces text matching a regular expression. In the replace text, use "$1" to refer to group 1 in the regular expression, and "$$" to mean a single dollar character. If use_empty_if_no_match (optional, default false) is true, and the expression does not match, results in null. For more information on regular expressions, see Regular expressions guide [14] |
| REPT | REPT(text, number_times) | Repeats text a given number of times. Use REPT to fill a cell with a number of instances of a text string. |
| RIGHT | RIGHT(text, num_chars) | Returns the specified number of characters from the end of a text string. |
| ROUND (Omniscope 2.8+) |
ROUND(number, num_digits) | Rounds a number to a specified number of digits. For example: ROUND(123.7825, 2) = 123.78 ROUND(123.456, 1) = 123.5 ROUND(123.456, -2) = 100); |
| ROWINDEXSUBSET (Omniscope 2.7+) |
ROWINDEXSUBSET(rowIndex, operator) In scripts: rowIndexSubset(rowIndex, operator) |
Results in a subset matching the row index(es) specified. Row indexes start from 1. Custom operator should be one of: "=", "<>", ">", ">=", "<", "<=" If not specified, "=" (equals) is used. |
| RUNNINGTOTAL (Omniscope 2.6+; 2.8+ for sortOrder) |
RUNNINGTOTAL(field, subset, sortOrder) | Evaluates to the running total in field for all data (if subset is not specified), or a subset (if subset is specified). The subset should be a data subset as evaluated using the SUBSET function. If sortOrder is true, values will sum in ascending order. If false, in descending order. If null or missing, in record order. |
| SCRIPT (Omniscope 2.6+; only with Java 6; some scripting functions require Omniscope 2.7+) |
SCRIPT(script, var1Name, var1Value, var2Name, var2Value, var3Name, var3Value..., timeout) | Executes a javascript expression. Requires Java 6, included with the full Omniscope installer. Supports core Javascript 1.5, but not browser-related objects. The script will be terminated after 10 seconds unless "timemout" is specified (in milliseconds). Note: you can use back-quotes (`) instead of normal quotes to quote your script, such as: `1 + 2`. Unlike with normal quotes, back-quoted text can contain any other character including backslash. For literal back-quotes, use two, e.g. SCRIPT(`var x = "Her name was ``Jane``";`) You must ensure you declare any dependencies (referenced fields inside your script) using the DEPENDENCIES function. For more information please click here [15]. |
| SEARCH | SEARCH(find_text, within_text, start_num) | Returns the number of the character at which a specific character or text string is first found, reading from left to right (not case-sensitive). The first character is numbered 1. Returns null if not found. |
| SEARCHREGEX | SEARCHREGEX(reg_expr, within_text, start_num) | Returns the number of the character at which a regular expression is first found, reading from left to right (not case-sensitive). The first character is numbered 1. Returns null if not found. For more information on regular expressions, see Regular expressions guide [14] |
| SIGN | SIGN(number) | Returns the sign of a number: 1 if the number is positive, zero if the number is zero, or -1 if the number is negative. |
| SIN | SIN(number) | Returns the sine of an angle. |
| SINH | SINH(number) | Returns the hyperbolic sine of a number. |
| SOUNDEX (Omniscope 2.8+) |
SOUNDEX(word) In scripts: soundex(word) |
Converts a text value containing a single word into its Soundex [16] phonetic code. |
| SQRT | SQRT(number) | Returns the square root of a number. |
| STARTSWITH (Omniscope 2.6+) |
STARTSWITH(text, sub_text) | Returns true if [sub_text] occurs in the beginning of [text] (case insensitive). |
| SUBSET (Omniscope 2.5+; Omniscope 2.6+ for custom operators) |
SUBSET(field, field_value, field_operator) In scripts: subset(field, field_value, field_operator) |
Evaluates to a subset of the data. Normally used only as an argument to another function. Either: (a) all records (if no arguments are specified); or (b) a current subset of records (if field is specified); or (c) another subset of records (if field and field_value are specified); or (d) another subset of records, using a custom operator (if all arguments are specified). Custom operator should be one of: "=", "<>", ">", ">=", "<", "<=", "contains" (2.8+), "does-not-contain" (2.8+), "starts-with" (2.8+), "ends-with" (2.8+) For more information, please visit SUBSET functions [7]. |
| SUBSET2 (Omniscope 2.5+; Omniscope 2.6+ for custom operators) |
SUBSET2(field_1, field_2, field_1_value, field_2_value, field_1_operator, field_2_operator) In scripts: subset2(field_1, field_2, field_1_value, field_2_value, field_1_operator, field_2_operator) |
Evaluates to a subset of the data. Normally used only as an argument to another function. Either: (a) a current subset of records (if field_N is specified); or (b) another subset of records (if field_N and field_N_value are specified); or (c) another subset of records, using a custom operator (if all arguments are specified). Custom operator should be one of: "=", "<>", ">", ">=", "<", "<=", "contains" (2.8+), "does-not-contain" (2.8+), "starts-with" (2.8+), "ends-with" (2.8+) For more information, please visit SUBSET functions [7]. Deprecated - please use the SUBSET and INTERSECTION functions instead. |
| SUBSET3 (Omniscope 2.5+; Omniscope 2.6+ for custom operators) |
SUBSET3(field_1, field_2, field_3, field_1_value, field_2_value, field_3_value, field_1_operator, field_2_operator, field_3_operator) In scripts: subset3(field_1, field_2, field_3, field_1_value, field_2_value, field_3_value, field_1_operator, field_2_operator, field_3_operator) |
Evaluates to a subset of the data. Normally used only as an argument to another function. Either: (a) a current subset of records (if field_N is specified); or (b) another subset of records (if field_N and field_N_value are specified); or (c) another subset of records, using a custom operator (if all arguments are specified). Custom operator should be one of: "=", "<>", ">", ">=", "<", "<=", "contains" (2.8+), "does-not-contain" (2.8+), "starts-with" (2.8+), "ends-with" (2.8+) For more information, please visit SUBSET functions [7]. Deprecated - please use the SUBSET and INTERSECTION functions instead. |
| SUBSET4 (Omniscope 2.5+; Omniscope 2.6+ for custom operators) |
SUBSET4(field_1, field_2, field_3, field_4, field_1_value, field_2_value, field_3_value, field_4_value, field_1_operator, field_2_operator, field_3_operator, field_4_operator) In scripts: subset4(field_1, field_2, field_3, field_4, field_1_value, field_2_value, field_3_value, field_4_value, field_1_operator, field_2_operator, field_3_operator, field_4_operator) |
Evaluates to a subset of the data. Normally used only as an argument to another function. Either: (a) a current subset of records (if field_N is specified); or (b) another subset of records (if field_N and field_N_value are specified); or (c) another subset of records, using a custom operator (if all arguments are specified). Custom operator should be one of: "=", "<>", ">", ">=", "<", "<=", "contains" (2.8+), "does-not-contain" (2.8+), "starts-with" (2.8+), "ends-with" (2.8+) For more information, please visit SUBSET functions [7]. Deprecated - please use the SUBSET and INTERSECTION functions instead. |
| SUBSET5 (Omniscope 2.5+; Omniscope 2.6+ for custom operators) |
SUBSET5(field_1, field_2, field_3, field_4, field_5, field_1_value, field_2_value, field_3_value, field_4_value, field_5_value, field_1_operator, field_2_operator, field_3_operator, field_4_operator, field_5_operator) In scripts: subset5(field_1, field_2, field_3, field_4, field_5, field_1_value, field_2_value, field_3_value, field_4_value, field_5_value, field_1_operator, field_2_operator, field_3_operator, field_4_operator, field_5_operator) |
Evaluates to a subset of the data. Normally used only as an argument to another function. Either: (a) a current subset of records (if field_N is specified); or (b) another subset of records (if field_N and field_N_value are specified); or (c) another subset of records, using a custom operator (if all arguments are specified). Custom operator should be one of: "=", "<>", ">", ">=", "<", "<=", "contains" (2.8+), "does-not-contain" (2.8+), "starts-with" (2.8+), "ends-with" (2.8+) For more information, please visit SUBSET functions [7]. Deprecated - please use the SUBSET and INTERSECTION functions instead. |
| SUBSET_EMPTYCOUNT (Omniscope 2.5+) |
SUBSET_EMPTYCOUNT(stat_field, subset) In scripts: subset_emptyCount(stat_field, subset) |
Calculates the statistical function [Number of empty values] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUBSET_FIRST (Omniscope 2.6+) |
SUBSET_FIRST(stat_field, subset) In scripts: subset_first(stat_field, subset) |
Calculates the statistical function [The first value (or null) in the original data order] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUBSET_FIRSTNONNULL (Omniscope 2.7+) |
SUBSET_FIRSTNONNULL(stat_field, subset) In scripts: subset_firstNonNull(stat_field, subset) |
Calculates the statistical function [The first non-null value in the original data order] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUBSET_LAST (Omniscope 2.6+) |
SUBSET_LAST(stat_field, subset) In scripts: subset_last(stat_field, subset) |
Calculates the statistical function [The last value (or null) in the original data order] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUBSET_LASTNONNULL (Omniscope 2.7+) |
SUBSET_LASTNONNULL(stat_field, subset) In scripts: subset_lastNonNull(stat_field, subset) |
Calculates the statistical function [The last non-null value in the original data order] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUBSET_MAX (Omniscope 2.5+) |
SUBSET_MAX(stat_field, subset) In scripts: subset_max(stat_field, subset) |
Calculates the statistical function [Maximum value (highest or last)] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUBSET_MEAN (Omniscope 2.5+) |
SUBSET_MEAN(stat_field, subset) In scripts: subset_mean(stat_field, subset) |
Calculates the statistical function [Mean (average) of values] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUBSET_MEDIAN (Omniscope 2.5+) |
SUBSET_MEDIAN(stat_field, subset) In scripts: subset_median(stat_field, subset) |
Calculates the statistical function [Median (middle) of values] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUBSET_MIN (Omniscope 2.5+) |
SUBSET_MIN(stat_field, subset) In scripts: subset_min(stat_field, subset) |
Calculates the statistical function [Minimum value (lowest or first)] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUBSET_MODE (Omniscope 2.5+) |
SUBSET_MODE(stat_field, subset) In scripts: subset_mode(stat_field, subset) |
Calculates the statistical function [Most common value (first if multimodal)] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUBSET_NONEMPTYCOUNT (Omniscope 2.5+) |
SUBSET_NONEMPTYCOUNT(stat_field, subset) In scripts: subset_nonEmptyCount(stat_field, subset) |
Calculates the statistical function [Number of non-empty values] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUBSET_PRODUCT (Omniscope 2.8+) |
SUBSET_PRODUCT(stat_field, subset) In scripts: subset_product(stat_field, subset) |
Calculates the statistical function [Product of values] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUBSET_RANGE (Omniscope 2.5+) |
SUBSET_RANGE(stat_field, subset) In scripts: subset_range(stat_field, subset) |
Calculates the statistical function [Range of values (maximum minus minimum)] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUBSET_SINGLETON (Omniscope 2.5+) |
SUBSET_SINGLETON(stat_field, subset) In scripts: subset_singleton(stat_field, subset) |
Calculates the statistical function [The single value, if there is one] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUBSET_STDDEV (Omniscope 2.5+) |
SUBSET_STDDEV(stat_field, subset) In scripts: subset_stdDev(stat_field, subset) |
Calculates the statistical function [Standard deviation of values from the mean] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUBSET_SUM (Omniscope 2.5+) |
SUBSET_SUM(stat_field, subset) In scripts: subset_sum(stat_field, subset) |
Calculates the statistical function [Sum (total) of values] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUBSET_UNIQUECOUNT (Omniscope 2.5+) |
SUBSET_UNIQUECOUNT(stat_field, subset) In scripts: subset_uniqueCount(stat_field, subset) |
Calculates the statistical function [Number of unique non-empty values] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUBSET_UNIQUESLIST (Omniscope 2.5+) |
SUBSET_UNIQUESLIST(stat_field, subset) In scripts: subset_uniquesList(stat_field, subset) |
Calculates the statistical function [A comma-separated list of all unique values] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. For more information, please visit SUBSET functions [7]. |
| SUM | SUM(number1, number2, ...) | Adds all the arguments. |
| TAN | TAN(number) | Returns the tangent of an angle. |
| TANH | TANH(number) | Returns the hyperbolic tangent of a number. |
| TEXT_LINE_COUNT | TEXT_LINE_COUNT(text) | Returns the number of lines (split by line-break) in a text value. |
| TEXTTODATE | TEXTTODATE(text_value, custom_format, lenient, time_zone) In scripts: textToDate(text_value, custom_format, lenient, time_zone) |
Converts text into a date. If custom_format is specified, this is a custom date format pattern such as "dd/MM/yyyy HH:mm:ss". If not specified, the default format for the current data locale will be used. If lenient is omitted or is true, this controls whether non-existent dates are permitted, such as 29 February on a non-leap-year (corrected to 1 March). If time zone value is specified, this controls how Omniscope interprets time values. If not specified, the text will be assumed to be a date/time from the same time zone as the system. For more information on date and time formats please click here [11]. |
| TEXTVALUE | TEXTVALUE(value, pattern) In scripts: textValue(value, pattern) |
Converts any value into the text equivalent, optionally using a format pattern. The format pattern (which must be quoted text) defines how numbers or dates are formatted. Warning: boolean values (true/false) will be translated using the current Language setting. Usage examples: TEXTVALUE(424) = "424" TEXTVALUE(123456.789 , "$###,###.###") = "$123,456.789" TEXTVALUE(DATEVALUE("02/06/2009") , "yyyy.MMMM.dd") = "2009.June.02" For more information on date and time formats please click here [11]. For more information on number formats please click here [17]. |
| TODAY (Omniscope 2.5+) |
TODAY() | Returns the current date. |
| TRENDVALUE (Omniscope 2.8+) |
TRENDVALUE(xField, yField, subset, xValue) In scripts: trendValue(xField, yField, subset, xValue) |
Evaluates the linear trend for X and Y fields, then evaluates the Y value for X value specified. If 'xValue' is omitted, uses the current record's X value. Used to determine the Y coordinate in a best-fit line showing the trend of two fields. If 'subset' is omitted, the full dataset is used. |
| TRIM | TRIM(text) | Removes all spaces from a text string except for single spaces between words. |
| TYPEOF (Omniscope 2.6+) |
TYPEOF(arg) | Returns the type of the argument. |
| TZCORRECT (Omniscope 2.8+) |
TZCORRECT(date, input_timezone, output_timezone) In scripts: tzCorrect(date, input_timezone, output_timezone) |
Corrects dates in the wrong timezone. Converts from one timezone to another, preserving the same logical local time in each timezone. Observes the current and historical rules for time zone offset and daylight saving according to the Olson time zone database. For example, if your data was recorded as 9am in time zone X, but it should have been recorded as 9am in time zone Y, you would use: TZCORRECT(date, X, Y) If either time zone is missing, your file's time zone will be used, as configured in the Regional Settings dialog, which defaults to your local system time zone. |
| TZDEFAULT (Omniscope 2.8+) |
TZDEFAULT() In scripts: tzDefault() |
Returns the Olson ID for the default time zone for this file, as configured in the Regional Settings dialog, which defaults to your local system time zone. |
| TZOFFSET (Omniscope 2.8+) |
TZOFFSET(time_zone, date) In scripts: tzOffset(time_zone, date) |
Returns the UTC offset, in milliseconds, for the time zone specified. If time_zone is not supplied, your file's time zone will be used, as configured in the Regional Settings dialog, which defaults to your local system time zone. If date is specified, returns the offset for that date/time, observing the current and historical behaviour and daylight saving rules. If not specified, returns the current offset from UTC for standard time in that time zone (i.e. without daylight saving). |
| UNION (Omniscope 2.6+) |
UNION(subset1, subset2, ...) In scripts: union(subset1, subset2, ...) |
Returns the data subset which is the union of records for all data subset arguments. If a record is present in ANY supplied subset, it will be present in the result. WARNING: this is an experimental function that has not been optimised for performance. Use alternative solutions such as extra formulas and the SUBSET function if performance is unacceptable. For more information, please visit SUBSET functions [7]. |
| UNIX_MILLISECONDS_TO_DATE (Omniscope 3.0+) |
UNIX_MILLISECONDS_TO_DATE(unixtime) In scripts: unixMillisecondsToDate(unixtime) |
Converts a number of milliseconds since unix epoch (00:00 1 January 1970 UTC) to a date. |
| UNIX_SECONDS_TO_DATE (Omniscope 3.0+) |
UNIX_SECONDS_TO_DATE(unixtime) In scripts: unixSecondsToDate(unixtime) |
Converts a number of seconds since unix epoch (00:00 1 January 1970 UTC) to a date. |
| UPPER | UPPER(text) | Converts all letters in a text string to uppercase. |
| VALUE | VALUE(text) | Converts a text string that represents a number to a number, or date text into a date, where possible, otherwise resulting in a text value. |
| XPATH (Omniscope 2.6+) |
XPATH(xml_data, xpath_expression) | Executes an XPath expression against an XML document. To obtain XML data, see the READRES function. For more information on XPath, see XPath guide [18] |
Scripting format is shown for functions available in Content View scripts, etc., from 2.7. More detail [19].
Below are some examples of formulae useful for calculating commonly-used fields:
Note: You can type function names or pick from the list; text strings in quotes should be entered literally; field names in [ ] should be input using the [Insert field ] tool in the Formula Editor. [3] Given that every Omniscope file is potentially a template file that will be refreshed with future data from the linked source(s), it is good practise to write formulae that always test for null or zero values that may appear in future refreshes, potentially creating errors in formulae.
To create a new column categorising values in a source column according to user-defined upper and lower limits:
=IF([SourceColumn]=null,null,IF[SourceColumn]<50,"0-50",IF[SourceColumn]<500,"50-500",">500"))
In this example, each value in [SourceColumn] is evaluated first to see if the value is null, otherwise it is placed in one of three 'bucketing' categories: 0-50, 50-500, or >500
Dates of payments and other events sometimes need to be categorised by fiscal rather than calendar year. One way to do this is to use the following formula, which can be extended to any number of years:
=IF([Date]=null,null,IF(DATEDIFF(DATEVALUE("1 Oct 2001"),[Date],"day")<366,"FY2002",IF(DATEDIFF(DATEVALUE("1 Oct 2002"),[Date],"day")<366,"FY2003","Out of range")))
In this example, the company's fiscal year runs from October, and the formula column Fiscal Year will be populated with null, FY2002, FY2003, or "out of range" depending on the value in the [Date] field.
Date fields can be translated into various transformations and sub-components by specifying a custom output date format [20] as the second argument in the DATETOTEXT function. For example:
=DATETOTEXT([DateField],"w") ...this formula evaluates [DateField] and returns the corresponding week number.
=DATETOTEXT([DateField],"EEEE") ...this formula evaluates [DateField] and returns the corresponding day of the week
An especially useful version of this is used to create duplicate date columns typed as Categories which sort:
=DATETOTEXT([DateField],"yyyy-MM-dd")
You can then Pane views by this categorised date, and use category tick-boxes with the dates naturally in the correct sort order.
Often it is useful to categorise records based on their rank in a certain column, i.e. a "Top 10" category. The formula below assigns the category value "Top 10" to any record whose non-null value in column B is ranked 10 or less:
=IF(AND([B] != null, RANK([B])<=10), "Top 10", null)
Note: '!=' means 'not equal'. Having creating the dynamically-evaluated Category value "Top 10", you can then filter on it and define a Top 10 Named Query data subset such that other views can be set to display only the current Top 10 list of records.
Example File: Ranking Top 10 and Bottom 5 [21] ; Example File: Ranking Data Subsets [22]
Using a Variable to define the threshold, you can flag Values which are outside a user-selectable upper-lower tolerance range:
=IF(OR([Value]<(-1*{Threshold variable}),[Value]>{Threshold variable}),"Flagged","Not Flagged")
Before writing the formula, you must define the Threshold Variable, its min, max and default values
Counting the number of times a particular value appears in a column:
=DATASET_NONEMPTYCOUNT("Column Name","Column Name", [Insert field-Column Name])
The first free text input "Column Name" specifies the column, the second the non-empty and the last is an [Insert Field] of the field 'Column Name' to pick up the values. This admittedly obscure syntax will return for each row the total number of times the value in the row appears in that same column in the entire data set.
Sometimes incoming data sets have null values and for aggregation purposes these values need to be converted to zeros:
=SUM([Field containing nulls])
This formula reads the values in any number of fields, and if they are all null, will return a zero for that row
Unlike spreadsheets, Omniscope formulae do not reference cells or rows directly, but common calculations involving periodic differences over time can be done using Date functions and Subset functions, as illustrated by the attached file which calculates price changes on a security which is only traded on weekdays:
Example file - Calculating Periodic Changes over Time [23]
This page describes the latest functionality available in Omniscope 2.6 b607 and later. If you are using 2.5 or an earlier version of 2.6, please see the older guide [24].
SUBSET functions are unique to Omniscope and are broken down into two sub-classes of functions which work together:
Note: these replace the previous, now deprecated DATASET_... functions as they are more flexible and efficient. Other functions other than SUBSET_MEAN/SUM/etc. also use SUBSET 'clauses' such as RANK.
The new INTERSECTION, UNION and INVERSE functions are classed as experimental because they have not been optimised for performance. If you find they perform too poorly for your data size, please continue to use the older SUBSET2 etc. functions documented here [24]. Performance improvements are scheduled for 2.7.
| If you wanted to find: | The sum of Sales Volume for the current country |
which could be rewritten as: | Sum of Sales Volume in subset: [all records with the same Country as the record being evaluated] |
you would use the formula: | SUBSET_SUM([Sales Volume], SUBSET([Country])) |
SUBSET [25] 'clauses' results in a data subset for use in other functions (such as SUBSET_MEAN or RANK). You would not normally use the result of SUBSET 'clause' as the end result of the entire formula, since you cannot display the definition of the subset defined as a data table inside a cell.
SUBSET [25] 'clauses' are used to identify records by one constraint (e.g. Month is "February"). To identify records by multiple constraints, or use more complex logic, combine SUBSET [25] with INTERSECTION [26], UNION [27] and INVERSE [28] (e.g. All of records in [Month is "February"] and [Client is "Acme Bank"]).
| SUBSET() | The entire dataset |
| SUBSET([Month]) | Data subset with the same Month field value as the record being evaluated |
| SUBSET([Month], "February") | Data subset with the Month field value 'February' |
SUBSET([Quantity], 5) | Data subset where the field/column Quantity value equals 5 |
| SUBSET([Quantity], 5, "<") SUBSET([Quantity], 5, "<=") SUBSET([Quantity], 5, ">") SUBSET([Quantity], 5, ">=") SUBSET([Quantity], 5, "=") SUBSET([Quantity], 5, "<>") | Data subsets where the field/column Quantity value is less than, less than/equal, greater than, greater than/equal, equal, not equal to the value 5 (respectively). Use of the "operator" inequality options requires Omniscope 2.6+. |
SUBSET([Surname], "Mac", "starts-with") | Data subsets where the field Surname begins with "Mac" such as "MacDonald", or contains "-" such as a double-barrelled name, etc. (2.8+) |
INTERSECTION( SUBSET([Month]), SUBSET([Client]) | Data subset with the same Month and Client field values as the record being evaluated |
INTERSECTION( SUBSET([Month], "February" ),
SUBSET([Client], "Acme Bank" ) )
| Data subset with the Month and Client field values 'February' and 'Acme Bank' |
INTERSECTION( SUBSET([Month] ),
SUBSET([ Client ]),
SUBSET([Country] ) | Data subset with the same Month, Client and Country field values as the record being evaluated
|
INTERSECTION( SUBSET([Month],
), "February"
SUBSET([ Client ],Acme Bank " " ),
SUBSET([Country], "UK" ) | Data subset with the Month, Client and Country field values 'February', 'Acme Bank' and 'UK' |
INTERSECTION( SUBSET([Month], "February", "=" ),
SUBSET([ Client ],Acme Bank " " ,"= " ),
SUBSET([Quantity], 5, ">=" ) | Data subset where the Month and Client field values are 'February' and 'Acme Bank', and the Quantity field values are greater than or equal to 5. |
SUBSET_... functions (such as SUBSET_MEAN [29]) accept a field for the statistical function and an optional data subset 'clause' to restrict the record set.
SUBSET_MEAN([Price]) | The mean of the Price field, for all records |
| SUBSET_SUM([Price], SUBSET([Month])) | The sum of the Price field, for the data subset with the same Month field value as the record being evaluated |
| SUBSET_MODE([Currency], SUBSET([Month], "February")) | The most common Currency field value, for the data subset with the Month field value 'February' |
This example shows a table of data containing Traders and their Sales Volume by Country. We want to find out the total Sales Volume for each Trader.
Country | Trader | Sales Volume | Formula field |
| UK | John Swires | 10,000 | 60,000 |
| France | John Swires | 15,000 | 60,000 |
| USA | John Swires | 35,000 | 60,000 |
| UK | Anne Campbell | 7,000 | 21,000 |
| Japan | Anne Campbell | 14,000 | 21,000 |
The field "Formula field" above is defined with the formula:
SUBSET_SUM([Sales Volume], SUBSET([Trader]))
Broken down, this means:
SUBSET([Trader]) The records with the same Trader value as the record being evaluated
SUBSET_SUM([Sales Volume], subset) The sum of Sales Volume for those records
When Omniscope evaluates the first cell (60,000) in "Formula field":
SUBSET([Trader]) evaluates to all records with Trader "John Swires" (i.e. the first 3 records).
SUBSET_SUM([Sales Volume], subset) evaluates to 60,000 (10,000 + 15,000 + 35,000).
This example involves a table of data containing multiple quotes for multiple parts to multiple clients in multiple currencies. We want to find the lowest Quote in "USD" for each combination of Part and Customer.
Customer | Currency | Part | Quote | Min USD Quote | ||
Alpha | GBP | widget | 8 |
|
| 12 |
Beta | USD | gromett | 10 |
|
| 10 |
Gamma | Yen | nubbin | 50 |
|
| 6 |
Alpha | USD | widget | 12 |
|
| 12 |
Gamma | USD | widget | 9 |
|
| 9 |
Beta | Euro | gromett | 11 |
|
| 10 |
| Alpha | Yen | nubbin | 52 | 6 | ||
| Beta | USD | nubbin | 5 | 5 | ||
| Gamma | USD | gromett | 7 | 7 | ||
| Alpha | USD | nubbin | 6 | 6 | ||
| Gamma | USD | nubbin | 6 | 6 |
The formula field [Min USD Quote] above can be defined with the following formula:
SUBSET_MIN([Quote], INTERSECTION(SUBSET([Customer]), SUBSET([Currency], "USD"),
SUBSET([Part]))
Broken down, this formula means:
SUBSET_MIN( [Quote], find the lowest quotation in the column for the following subsets:
INTERSECTION(SUBSET([Customer]), SUBSET([Currency], "USD"), SUBSET([Part])) = all combinations of 'Customer' and 'Part' where Currency="USD"
The RANK function works much like the Excel RANK function, and allows you to infer the RANK of a value within a set of values. In Omniscope, the value can be any literal value or the value of a referenced field. The set of values must be all values within a named field, either for all records, or for a data subset.
Examples for the above Customer/Currency/Part/Quote/Min USD Quote data, where the Quote column has ordered values as follows:
Quote Rank 12 1 10 2 10 2 9 4 8 5 7 6 6 7 6 7 6 7 6 7 5 11
So, when evaluating the formula for a record where Quote is 8:
This page refers to the use of SUBSET functions in Omniscope 2.5 through to Omniscope 2.6 b606. In Omniscope 2.6 b607 or later, please see the updated guide [7].
SUBSET functions are unique to Omniscope and are broken down into two sub-classes of functions which work together:
Note: SUBSET functions replace the previous, now deprecated DATASET_... functions as they are more flexible and efficient. Other functions other than SUBSET_MEAN/SUM/etc. also use SUBSET 'clauses' such as RANK.
| If you wanted to find: | The sum of Sales Volume for the current country |
which could be rewritten as: | Sum of Sales Volume in subset (all records with the same Country as the record being evaluated) |
you would use the formula: | SUBSET_SUM([Sales Volume], SUBSET([Country])) |
SUBSET [25] 'clauses' results in a data subset for use in other functions (such as SUBSET_MEAN or RANK). You would not normally use the result of SUBSET 'clause' as the end result of the entire formula, since you cannot display the definition of the subset defined as a data table inside a cell.
SUBSET [25] 'clauses' are used to identify records by one constraint (e.g. Month is "February"), and SUBSET2 [33] is used to identify records by two constraints (e.g. Month is "February" and Client is "Acme Bank"), etc.
| SUBSET() | The entire dataset |
| SUBSET([Month]) | Data subset with the same Month field value as the record being evaluated |
| SUBSET([Month], "February") | Data subset with the Month field value 'February' |
SUBSET([Quantity], 5) | Data subset where the field/column Quantity value equals 5 |
| SUBSET([Quantity], 5, "<") SUBSET([Quantity], 5, "<=") SUBSET([Quantity], 5, ">") SUBSET([Quantity], 5, ">=") SUBSET([Quantity], 5, "=") SUBSET([Quantity], 5, "<>") | Data subsets where the filed/column Quantity value is less than, less than/equal, greater than, greater than/equal, equal, not equal to the value 5 (respectively). Use of the "operator" inequality options requires Omniscope 2.6+. |
| SUBSET2([Month], [Client]) | Data subset with the same Month and Client field values as the record being evaluated |
| SUBSET2([Month], [Client], "February", "Acme Bank") | Data subset with the Month and Client field values 'February' and 'Acme Bank' |
| SUBSET3([Month], [Client], [Country]) | Data subset with the same Month, Client and Country field values as the record being evaluated |
| SUBSET3([Month], [Client], [Country], "February", "Acme Bank", "UK") | Data subset with the Month, Client and Country field values 'February', 'Acme Bank' and 'UK' |
| SUBSET3([Month], [Client], [Quantity], "February", "Acme Bank", 5, "=", "=", ">=") | Data subset where the Month and Client field values are 'February' and 'Acme Bank', and the Quantity field values are greater than or equal to 5. Use of "operator" inequality options requires Omniscope 2.6+. |
SUBSET_... functions (such as SUBSET_MEAN [29]) accept a field for the statistical function and an optional data subset 'clause' to restrict the record set.
SUBSET_MEAN([Price]) | The mean of the Price field, for all records |
| SUBSET_SUM([Price], SUBSET([Month])) | The sum of the Price field, for the data subset with the same Month field value as the record being evaluated |
| SUBSET_MODE([Currency], SUBSET([Month], "February")) | The most common Currency field value, for the data subset with the Month field value 'February' |
This example shows a table of data containing Traders and their Sales Volume by Country. We want to find out the total Sales Volume for each Trader.
Country | Trader | Sales Volume | Formula field |
| UK | John Swires | 10,000 | 60,000 |
| France | John Swires | 15,000 | 60,000 |
| USA | John Swires | 35,000 | 60,000 |
| UK | Anne Campbell | 7,000 | 21,000 |
| Japan | Anne Campbell | 14,000 | 21,000 |
The field "Formula field" above is defined with the formula:
SUBSET_SUM([Sales Volume], SUBSET([Trader]))
Broken down, this means:
SUBSET([Trader]) The records with the same Trader value as the record being evaluated
SUBSET_SUM([Sales Volume], subset) The sum of Sales Volume for those records
When Omniscope evaluates the first cell (60,000) in "Formula field":
SUBSET([Trader]) evaluates to all records with Trader "John Swires" (i.e. the first 3 records).
SUBSET_SUM([Sales Volume], subset) evaluates to 60,000 (10,000 + 15,000 + 35,000).
This example involves a table of data containing multiple quotes for multiple parts to multiple clients in multiple currencies. We want to find the lowest Quote in "USD" for each combination of Part and Customer.
Customer | Currency | Part | Quote | Min USD Quote | ||
Alpha | GBP | widget | 8 |
|
| 12 |
Beta | USD | gromett | 10 |
|
| 10 |
Gamma | Yen | nubbin | 50 |
|
| 6 |
Alpha | USD | widget | 12 |
|
| 12 |
Gamma | USD | widget | 9 |
|
| 9 |
Beta | Euro | gromett | 11 |
|
| 10 |
| Alpha | Yen | nubbin | 52 | 6 | ||
| Beta | USD | nubbin | 5 | 5 | ||
| Gamma | USD | gromett | 7 | 7 | ||
| Alpha | USD | nubbin | 6 | 6 | ||
| Gamma | USD | nubbin | 6 | 6 |
The formula field [Min USD Quote] above can be defined with the following formula:
SUBSET_MIN([Quote],SUBSET3([Customer],[Currency],[Part],[Customer],"USD",[Part]))
Broken down, this formula means:
SUBSET_MIN( [Quote], find the lowest quotation in the column for the following subsets:
SUBSET3([Customer],[Currency],[Part],[Customer],"USD",[Part] ) = all combinations of 'Customer' and 'Part' where Currency="USD"
The DECLARE function allows you to declare a value using an expression (mini formula), then use that value repeatedly within the rest of your formula.
It is highly useful in complex formulae where you find yourself repeating the same sub-formula many times, as it makes your formula much clearer, and can yield better performance.
In its simplest form, DECLARE allows you to declare one named value as follows:
DECLARE(
myValue, 1+2+3,
myValue*myValue + myValue
)
(Result: 6)
The first two parameters are equivalent to saying "Let myValue = 1+2+3" and declare the value "myValue" as the result of "1+2+3" (i.e. 6). Here myValue is a made-up name which can be whatever you want providing you do not use spaces or numeric operator characters, and no field or variable already exists with the same name.
The last parameter is the formula to evaluate in the knowledge that "myValue" is equal to "6".
This is the same as the pseudo-code:
LET myValue = 1 + 2 + 3
RESULT = myValue * myValue * myValue
This would be the same as the more repetitive formula:
(1+2+3)*(1+2+3) + (1+2+3)
Multiple values can be declared by providing more pairs of [name, value] arguments at the start, as seen in this example, which takes a date field (Maturity Date) and breaks it into the numeric Month and Year values, before converting into a long textual representation of that date.
DECLARE(
month, DATEUNIT(Maturity Date, "month"),
year, DATEUNIT(Maturity Date, "year"),
IF(
month<=3, "1st quarter",
month<=6, "2nd quarter",
month<=9, "3rd quarter",
"4th quarter"
)
+ " of year " + MOD(year, 100) + ", " +
IF(
year < 1900, "before last century",
year < 2000, "last century",
year < 2100, "next century",
"after next century"
)
)
(Example result: "2nd quarter of year 7, next century")
This is the same as the pseudo-code:
LET month = [month number for Maturity Date]
LET year = [year number for Maturity Date
RESULT = [various calculations using month and year]
This would be the same as the more repetitive formula, which is more error-prone and less clear:
IF(
DATEUNIT(Maturity Date, "month")<=3, "1st quarter",
DATEUNIT(Maturity Date, "month")<=6, "2nd quarter",
DATEUNIT(Maturity Date, "month")<=9, "3rd quarter",
"4th quarter"
)
+ " of year " + MOD(year, 100) + ", "
IF(
DATEUNIT(Maturity Date, "year") < 1900, "before last century",
DATEUNIT(Maturity Date, "year") < 2000, "last century",
DATEUNIT(Maturity Date, "year") < 2100, "next century",
"after next century"
)
Web services, many of which are free, can be incorporated into any Omniscope file in two ways:
1). Use the Settings > Web Services > Add web service dialog to add your services to any Omniscope file containing a column of values acceptable as the input parameter(s). Use a Formula field to 'add' multiple parameters and delimiters to define a multi-field input 'slate'
2). Some web services can be written directly into Omniscope formula fields as shown below
It is possible to access web services values using formula fields defined in the file itself and re-evaluated whenever the file is opened or data is refreshed.
Example: stock price look-up formula that uses Yahoo Finance as the source based on submission of exchange ticker from the [Ticker] column in the data set, then multiplies by number of shares [No. Shares] to obtain real-time [Current Value] of holdings:
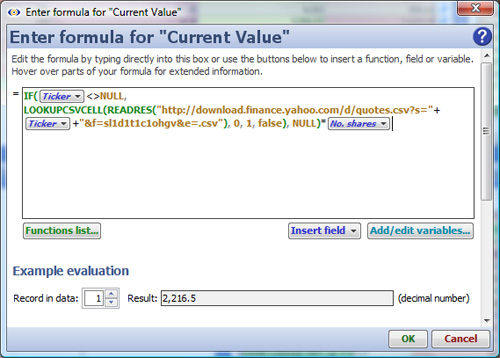
Example: real-time foreign exchange conversions, where [Currency] is the currency pair to be converted in a field in the data set, e.g. GBPUSD. Use the URL below inside a formula syntax similar to the one shown in the Formula Editor screenshot above:
http://download.finance.yahoo.com/d/quotes.csv?s="+[Currency]+"=X&f=sl1d1t1c1ohgv&e=.csv
Note: when preparing your data sets, be aware of the upper/lower case sensitivity for any web services you plan to draw on. Test the format of the input parameter before preparing your data. For example, the sample web services links below all require a lowercase U.S. stock ticker symbol. Add as many web services as you want, using any number of Omniscope Web Views to display the automatically-generated results from posting the user-selected row values as inputs. If necessary, use Omniscope Operations tools like Summarise fields or Expand/Collapse fields to modify your data to match the required format of the web service input parameter.
The services below all accept a lowercase US stock ticker as the web service parameter:
Table Chart: for each Symbol, returns Last Trade, Trade Time, Change, Volume and Todays Price:
http://appsupport.visokio.com/appsupport/symbolPrices.cfm [35]
Line Chart: for each Symbol, shows Price over time for the day:
http://appsupport.visokio.com/appsupport/yahooFinanceTodaysPrice.cfm [36]
Line Chart: for each Symbol, shows Price over the past year:
http://appsupport.visokio.com/appsupport/yahooFinanceYearPrice.cfm [37]
Omniscope includes a test web service that 'echos' whatever field (column) of values are selected in the current tab. Try configuring this web service using the default Visokio URL given, with a name like 'Echo Test', and select any field in your data set. Switch to one of the views in Omniscope, and select less than 100 records, then (on the newly-added Main Toolbar web services menu button) click on the 'Echo Test' web service button. If you have configured a Web View to display the web service results, they will appear in that open Web View. If you have not configured a Web View in Omniscope, your default browser will open and display the echo results, which are being returned from a Visokio server.
This section lists functions available in earlier versions of Omniscope which have been classified as "deprecated". Although these functions still work, there are now better ways of achieving the same result in more recent versions of Omniscope. These will continue to be supported for the medium term but may be withdrawn from Omniscope after several major releases.
See also: Non-deprecated functions [38] Guide to SUBSET (replacing DATASET) functions [7]
Function | Usage | Description |
| DATASET_EMPTYCOUNT | DATASET_EMPTYCOUNT(stat_field, subset_field, subset_field_value) | Calculates the statistical function [Number of empty values] of a field. Either: (a) for all records (if only stat_field is specified); or (b) for a current subset of records (if subset_field is specified); or (c) for another subset of records (if subset_field and subset_field_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_EMPTYCOUNT2 | DATASET_EMPTYCOUNT2(stat_field, subset_field_1, subset_field_2, subset_field_1_value, subset_field_2_value) | Calculates the statistical function [Number of empty values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_EMPTYCOUNT3 | DATASET_EMPTYCOUNT3(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_1_value, subset_field_2_value, subset_field_3_value) | Calculates the statistical function [Number of empty values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_EMPTYCOUNT4 | DATASET_EMPTYCOUNT4(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value) | Calculates the statistical function [Number of empty values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_EMPTYCOUNT5 | DATASET_EMPTYCOUNT5(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_5, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value, subset_field_5_value) | Calculates the statistical function [Number of empty values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MAX | DATASET_MAX(stat_field, subset_field, subset_field_value) | Calculates the statistical function [Maximum value (highest or last)] of a field. Either: (a) for all records (if only stat_field is specified); or (b) for a current subset of records (if subset_field is specified); or (c) for another subset of records (if subset_field and subset_field_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MAX2 | DATASET_MAX2(stat_field, subset_field_1, subset_field_2, subset_field_1_value, subset_field_2_value) | Calculates the statistical function [Maximum value (highest or last)] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MAX3 | DATASET_MAX3(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_1_value, subset_field_2_value, subset_field_3_value) | Calculates the statistical function [Maximum value (highest or last)] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MAX4 | DATASET_MAX4(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value) | Calculates the statistical function [Maximum value (highest or last)] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MAX5 | DATASET_MAX5(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_5, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value, subset_field_5_value) | Calculates the statistical function [Maximum value (highest or last)] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MEAN | DATASET_MEAN(stat_field, subset_field, subset_field_value) | Calculates the statistical function [Mean (average) of values] of a field. Either: (a) for all records (if only stat_field is specified); or (b) for a current subset of records (if subset_field is specified); or (c) for another subset of records (if subset_field and subset_field_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MEAN2 | DATASET_MEAN2(stat_field, subset_field_1, subset_field_2, subset_field_1_value, subset_field_2_value) | Calculates the statistical function [Mean (average) of values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MEAN3 | DATASET_MEAN3(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_1_value, subset_field_2_value, subset_field_3_value) | Calculates the statistical function [Mean (average) of values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MEAN4 | DATASET_MEAN4(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value) | Calculates the statistical function [Mean (average) of values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MEAN5 | DATASET_MEAN5(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_5, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value, subset_field_5_value) | Calculates the statistical function [Mean (average) of values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MEDIAN | DATASET_MEDIAN(stat_field, subset_field, subset_field_value) | Calculates the statistical function [Median (middle) of values] of a field. Either: (a) for all records (if only stat_field is specified); or (b) for a current subset of records (if subset_field is specified); or (c) for another subset of records (if subset_field and subset_field_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MEDIAN2 | DATASET_MEDIAN2(stat_field, subset_field_1, subset_field_2, subset_field_1_value, subset_field_2_value) | Calculates the statistical function [Median (middle) of values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MEDIAN3 | DATASET_MEDIAN3(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_1_value, subset_field_2_value, subset_field_3_value) | Calculates the statistical function [Median (middle) of values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MEDIAN4 | DATASET_MEDIAN4(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value) | Calculates the statistical function [Median (middle) of values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MEDIAN5 | DATASET_MEDIAN5(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_5, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value, subset_field_5_value) | Calculates the statistical function [Median (middle) of values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MIN | DATASET_MIN(stat_field, subset_field, subset_field_value) | Calculates the statistical function [Minimum value (lowest or first)] of a field. Either: (a) for all records (if only stat_field is specified); or (b) for a current subset of records (if subset_field is specified); or (c) for another subset of records (if subset_field and subset_field_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MIN2 | DATASET_MIN2(stat_field, subset_field_1, subset_field_2, subset_field_1_value, subset_field_2_value) | Calculates the statistical function [Minimum value (lowest or first)] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MIN3 | DATASET_MIN3(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_1_value, subset_field_2_value, subset_field_3_value) | Calculates the statistical function [Minimum value (lowest or first)] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MIN4 | DATASET_MIN4(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value) | Calculates the statistical function [Minimum value (lowest or first)] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MIN5 | DATASET_MIN5(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_5, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value, subset_field_5_value) | Calculates the statistical function [Minimum value (lowest or first)] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MODE | DATASET_MODE(stat_field, subset_field, subset_field_value) | Calculates the statistical function [Most common value (first if multimodal)] of a field. Either: (a) for all records (if only stat_field is specified); or (b) for a current subset of records (if subset_field is specified); or (c) for another subset of records (if subset_field and subset_field_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MODE2 | DATASET_MODE2(stat_field, subset_field_1, subset_field_2, subset_field_1_value, subset_field_2_value) | Calculates the statistical function [Most common value (first if multimodal)] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MODE3 | DATASET_MODE3(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_1_value, subset_field_2_value, subset_field_3_value) | Calculates the statistical function [Most common value (first if multimodal)] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MODE4 | DATASET_MODE4(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value) | Calculates the statistical function [Most common value (first if multimodal)] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_MODE5 | DATASET_MODE5(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_5, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value, subset_field_5_value) | Calculates the statistical function [Most common value (first if multimodal)] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_NONEMPTYCOUNT | DATASET_NONEMPTYCOUNT(stat_field, subset_field, subset_field_value) | Calculates the statistical function [Number of non-empty values] of a field. Either: (a) for all records (if only stat_field is specified); or (b) for a current subset of records (if subset_field is specified); or (c) for another subset of records (if subset_field and subset_field_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_NONEMPTYCOUNT2 | DATASET_NONEMPTYCOUNT2(stat_field, subset_field_1, subset_field_2, subset_field_1_value, subset_field_2_value) | Calculates the statistical function [Number of non-empty values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_NONEMPTYCOUNT3 | DATASET_NONEMPTYCOUNT3(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_1_value, subset_field_2_value, subset_field_3_value) | Calculates the statistical function [Number of non-empty values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_NONEMPTYCOUNT4 | DATASET_NONEMPTYCOUNT4(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value) | Calculates the statistical function [Number of non-empty values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_NONEMPTYCOUNT5 | DATASET_NONEMPTYCOUNT5(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_5, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value, subset_field_5_value) | Calculates the statistical function [Number of non-empty values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_PRODUCT | DATASET_PRODUCT(stat_field, subset_field, subset_field_value) | Calculates the statistical function [Product of values] of a field. Either: (a) for all records (if only stat_field is specified); or (b) for a current subset of records (if subset_field is specified); or (c) for another subset of records (if subset_field and subset_field_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_PRODUCT2 | DATASET_PRODUCT2(stat_field, subset_field_1, subset_field_2, subset_field_1_value, subset_field_2_value) | Calculates the statistical function [Product of values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_PRODUCT3 | DATASET_PRODUCT3(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_1_value, subset_field_2_value, subset_field_3_value) | Calculates the statistical function [Product of values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_PRODUCT4 | DATASET_PRODUCT4(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value) | Calculates the statistical function [Product of values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_PRODUCT5 | DATASET_PRODUCT5(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_5, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value, subset_field_5_value) | Calculates the statistical function [Product of values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_RANGE | DATASET_RANGE(stat_field, subset_field, subset_field_value) | Calculates the statistical function [Range of values (maximum minus minimum)] of a field. Either: (a) for all records (if only stat_field is specified); or (b) for a current subset of records (if subset_field is specified); or (c) for another subset of records (if subset_field and subset_field_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_RANGE2 | DATASET_RANGE2(stat_field, subset_field_1, subset_field_2, subset_field_1_value, subset_field_2_value) | Calculates the statistical function [Range of values (maximum minus minimum)] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_RANGE3 | DATASET_RANGE3(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_1_value, subset_field_2_value, subset_field_3_value) | Calculates the statistical function [Range of values (maximum minus minimum)] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_RANGE4 | DATASET_RANGE4(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value) | Calculates the statistical function [Range of values (maximum minus minimum)] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_RANGE5 | DATASET_RANGE5(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_5, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value, subset_field_5_value) | Calculates the statistical function [Range of values (maximum minus minimum)] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_RECORDCOUNT | DATASET_RECORDCOUNT(stat_field, subset_field, subset_field_value) | Calculates the statistical function [Number of records] of a field. Either: (a) for all records (if only stat_field is specified); or (b) for a current subset of records (if subset_field is specified); or (c) for another subset of records (if subset_field and subset_field_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_RECORDCOUNT2 | DATASET_RECORDCOUNT2(stat_field, subset_field_1, subset_field_2, subset_field_1_value, subset_field_2_value) | Calculates the statistical function [Number of records] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_RECORDCOUNT3 | DATASET_RECORDCOUNT3(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_1_value, subset_field_2_value, subset_field_3_value) | Calculates the statistical function [Number of records] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_RECORDCOUNT4 | DATASET_RECORDCOUNT4(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value) | Calculates the statistical function [Number of records] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_RECORDCOUNT5 | DATASET_RECORDCOUNT5(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_5, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value, subset_field_5_value) | Calculates the statistical function [Number of records] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_SINGLETON | DATASET_SINGLETON(stat_field, subset_field, subset_field_value) | Calculates the statistical function [The single value, if there is one] of a field. Either: (a) for all records (if only stat_field is specified); or (b) for a current subset of records (if subset_field is specified); or (c) for another subset of records (if subset_field and subset_field_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_SINGLETON2 | DATASET_SINGLETON2(stat_field, subset_field_1, subset_field_2, subset_field_1_value, subset_field_2_value) | Calculates the statistical function [The single value, if there is one] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_SINGLETON3 | DATASET_SINGLETON3(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_1_value, subset_field_2_value, subset_field_3_value) | Calculates the statistical function [The single value, if there is one] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_SINGLETON4 | DATASET_SINGLETON4(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value) | Calculates the statistical function [The single value, if there is one] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_SINGLETON5 | DATASET_SINGLETON5(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_5, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value, subset_field_5_value) | Calculates the statistical function [The single value, if there is one] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_STDDEV | DATASET_STDDEV(stat_field, subset_field, subset_field_value) | Calculates the statistical function [Standard deviation of values from the mean] of a field. Either: (a) for all records (if only stat_field is specified); or (b) for a current subset of records (if subset_field is specified); or (c) for another subset of records (if subset_field and subset_field_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_STDDEV2 | DATASET_STDDEV2(stat_field, subset_field_1, subset_field_2, subset_field_1_value, subset_field_2_value) | Calculates the statistical function [Standard deviation of values from the mean] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_STDDEV3 | DATASET_STDDEV3(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_1_value, subset_field_2_value, subset_field_3_value) | Calculates the statistical function [Standard deviation of values from the mean] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_STDDEV4 | DATASET_STDDEV4(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value) | Calculates the statistical function [Standard deviation of values from the mean] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_STDDEV5 | DATASET_STDDEV5(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_5, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value, subset_field_5_value) | Calculates the statistical function [Standard deviation of values from the mean] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_SUM | DATASET_SUM(stat_field, subset_field, subset_field_value) | Calculates the statistical function [Sum (total) of values] of a field. Either: (a) for all records (if only stat_field is specified); or (b) for a current subset of records (if subset_field is specified); or (c) for another subset of records (if subset_field and subset_field_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_SUM2 | DATASET_SUM2(stat_field, subset_field_1, subset_field_2, subset_field_1_value, subset_field_2_value) | Calculates the statistical function [Sum (total) of values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_SUM3 | DATASET_SUM3(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_1_value, subset_field_2_value, subset_field_3_value) | Calculates the statistical function [Sum (total) of values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_SUM4 | DATASET_SUM4(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value) | Calculates the statistical function [Sum (total) of values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_SUM5 | DATASET_SUM5(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_5, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value, subset_field_5_value) | Calculates the statistical function [Sum (total) of values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_UNIQUECOUNT | DATASET_UNIQUECOUNT(stat_field, subset_field, subset_field_value) | Calculates the statistical function [Number of unique non-empty values] of a field. Either: (a) for all records (if only stat_field is specified); or (b) for a current subset of records (if subset_field is specified); or (c) for another subset of records (if subset_field and subset_field_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_UNIQUECOUNT2 | DATASET_UNIQUECOUNT2(stat_field, subset_field_1, subset_field_2, subset_field_1_value, subset_field_2_value) | Calculates the statistical function [Number of unique non-empty values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_UNIQUECOUNT3 | DATASET_UNIQUECOUNT3(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_1_value, subset_field_2_value, subset_field_3_value) | Calculates the statistical function [Number of unique non-empty values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_UNIQUECOUNT4 | DATASET_UNIQUECOUNT4(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value) | Calculates the statistical function [Number of unique non-empty values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_UNIQUECOUNT5 | DATASET_UNIQUECOUNT5(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_5, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value, subset_field_5_value) | Calculates the statistical function [Number of unique non-empty values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_UNIQUESLIST | DATASET_UNIQUESLIST(stat_field, subset_field, subset_field_value) | Calculates the statistical function [A comma-separated list of all unique values] of a field. Either: (a) for all records (if only stat_field is specified); or (b) for a current subset of records (if subset_field is specified); or (c) for another subset of records (if subset_field and subset_field_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_UNIQUESLIST2 | DATASET_UNIQUESLIST2(stat_field, subset_field_1, subset_field_2, subset_field_1_value, subset_field_2_value) | Calculates the statistical function [A comma-separated list of all unique values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_UNIQUESLIST3 | DATASET_UNIQUESLIST3(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_1_value, subset_field_2_value, subset_field_3_value) | Calculates the statistical function [A comma-separated list of all unique values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_UNIQUESLIST4 | DATASET_UNIQUESLIST4(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value) | Calculates the statistical function [A comma-separated list of all unique values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| DATASET_UNIQUESLIST5 | DATASET_UNIQUESLIST5(stat_field, subset_field_1, subset_field_2, subset_field_3, subset_field_4, subset_field_5, subset_field_1_value, subset_field_2_value, subset_field_3_value, subset_field_4_value, subset_field_5_value) | Calculates the statistical function [A comma-separated list of all unique values] of a field. Either: (a) for a current subset of records (if subset_field_N is specified); or (b) for another subset of records (if subset_field_N and subset_field_N_value are specified). Deprecated - please use the SUBSET family of functions instead. |
| SUBSET_RECORDCOUNT (Omniscope 2.5+) |
SUBSET_RECORDCOUNT(stat_field, subset) In scripts: subset_recordCount(stat_field, subset) |
Calculates the statistical function [Number of records] of a field. Either: (a) for all records (if only field_name is specified); or (b) for a subset of data (if subset is specified). Use the SUBSET function to define a data subset. Deprecated - please use the RECORDCOUNT function instead. For more information, please visit SUBSET functions [7]. |
The DATASET_... functions (documented in Deprecated Functions [8]) were deprecated as of verson 2.5. New SUBSET functions, in combination with other existing functions, are more flexible and efficient.
See also: Functions Guide [38] Guide to SUBSET functions [7] Deprecated Functions [8]
The Formula Editor dialog in Omniscope is a powerful tool for creating and editing an Omniscope formula. For more general information about adding formulae to your files, see Formula Fields [39].
The large white box is the formula itself. This box can be edited just like a text field in a form. You can type your formula in from scratch, or use the buttons underneath to help you insert elements of the formula.
Field and variable references are shown inside the text as little embedded buttons, but these behave like characters in the text, and can be selected, cut, copied, pasted and deleted just like other text. Additionally, you can click each embedded button to change the field or variable.
Field references can be inserted using the Insert field below the formula box. Variable [4] references can be inserted using Insert variable except you will need to define the variable beforehand using Add/edit variables [4].
Alternatively, you can type the field/variable name directly (but if it has punctuation or spaces, you will need to enclose the name in [square brackets]).
Colours are used to identify different parts of the formula. For example, green indicates a function such as SUM(...), blue indicates a field reference, and cyan/turquoise indicates a variable reference.
During a session with the formula editor, use Ctrl+Z to undo your edits, and Ctrl+Y or Ctrl+Shift+Z to redo edits you have undone. Accidentally deleted half an hour's work? Ctrl+Z will bring it back.
Once you have clicked OK, the edited formula will be applied and your fields will recalculate. At this point, from the main Omniscope window, you can use Data > Undo edit or press Ctrl+Z to undo the entire formula editing session (from the point you opened the formula editor until you pressed OK).
If you know the function, simply type its name followed by an open bracket, e.g. "SUM(". Then provide any arguments/parameters to the function, separated by commas, ending with a close bracket. For example: "SUM(1, 2)".
If you are unsure how to use a particular function, type the function name and the open bracket, then move your mouse over the function. A tooltip will appear with guidance.
To browse and insert functions from a list, click Functions list [40]. In the dialog that appears, browse through the functions and read their syntax. Find the function you want and click OK. The function and sample usage will be inserted into the formula at the cursor position. This will typically introduce errors which will be highlighted, since you must change the sample argument/parameter names for real values, references or expressions. More... [40]
All standard spreadsheet functions are provided where appropriate for Omniscope, so you can expect POWER() to work in the same way as Excel, for example. Additional Omniscope-specific functions such as SUBSET are also provided.
See the Knowledge Base Functions Guide [2] for full documentation of all functions.
Long and complicated formulae can be hard to read and work with. Use spaces, tabs, line-breaks and comments to space-out and describe sections of the formula, without affecting calculation.
Comments must be surrounded with "/*" and "*/" as in the following example:
(1 + 1) /* adding some numbers */
/ 2 /* dividing in half */
The formula editor window can also be resized as large as needed when working on a very large formula.
While editing your formula, you can see the results in two ways:
In the section Example evaluation, use the Record in data spinner to select a record. Providing your formula has no errors, the result will be shown to the right, along with the data type. If you move the formula editor to one side, the same record will be highlighted in the views.
Move your mouse over the formula. As you move, different parts will become highlighted, and if you hold the mouse over a particular part, a tooltip will appear containing the result of that part of the formula when evaluated against the record chosen in Example evaluation.
For example, in the formula "(1 + 1) * 2", moving your mouse over the "+" will highlight "1 + 1" and the tooltip will show "1 + 1 = 2". Moving over the "*" will highlight "(1 + 1) * 2", and the tooltip will show "(1 + 1) * 2 = 4".
If your formula contains errors, these will be reported in red text in the Errors section. Guidance text deemed useful for a function in the formula will be shown. The relevant part of the formula will be highlighted in pink.
Omniscope contains an extensive list of standard and specialised functions you can use to define Formula fields. In addition to the standard functions (with the same syntax) found in spreadsheets like Excel, Omniscope also contains a library of powerful DATASET functions that operate on one or more columns and can define the subset of data for which calculations should be be done based on values in other columns.
In the Formula Editor [3], choose Functions list to see the following dialog.
 |  |
Each function is documented briefly in the functions list. For online documentation of available functions, including more detailed documentation of Omniscope-specific functions such as SUBSET(), consult our Functions Guide [41].
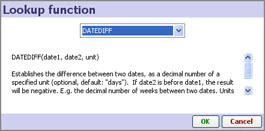 | 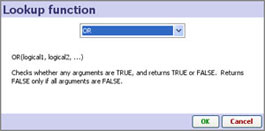 |
If you have questions about how to define formulae for specific tasks, consult the KnowledgeBase Useful Formulae [6] section. If you would like to propose additional functions you would find helpful, please post your ideas in the Forums [42] page.
Omniscope permits extremely powerful modelling with multiple sensitivity analyses in real-time using Variables you can define and insert in formula fields [39].
AS defined in Omniscope, Variables are input assumptions (not fields in the data set) you define by setting a default value and specifying upper and lower ranges. Variables are used as flexible assumption values (as opposed to factual/historic values in the data set) for making dynamic sensitivity analyses and real-time modelling options available to users of the file.
The value used in formulae containing variables can be modified by your users from the initial default using the Side Bar sliders corresponding to each variable. These sliders must be visible (ticked in the Devices drop-down menu on the Side Bar) in order for you and your users to 'flex' the assumptions by adjusting the current value of the variable. Any variable whose current value is different from the default will show a highlighted Side Bar slider device, as with active filter devices. As with filters, clicking Reset on the main toolbar reverts all variables to their configured default values.
Let's look at another example of a formula that uses a different type of Variable. In the example below (taken from the embedded demo presentation 'Cajun Sugar report', where each record is a sugar refinery), the IF function is used to test the 'Energy source' column value. Only if the value equals "Fuel", is the assumption Variable 'Oil Price' used to adjust the energy costs.
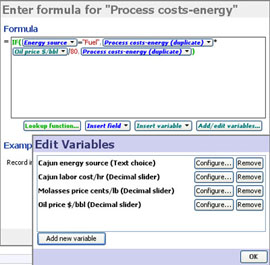 | 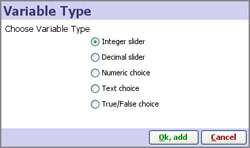 |
You must define Variables before they can be used in expressions defining the values in Formula fields [39]. Click on Add/Edit variables and you will be asked to specify one of 5 types of Variable, each of which has a Side Bar device and other rules associated with it:
 | 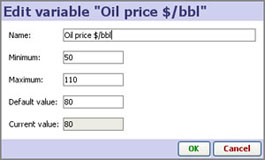 |
Depending on the type of Variable you are specifying, you will be asked to define one or more allowable values, or a range of values with a minimum, maximum and default. If you display the Side Bar devices associated with key input/assumption Variables, users can easily change any or all assumptions and see the calculated quantities and graphic visualisations updated in real time.
To specify different values for Variables, you can use the sliders, or you can type one or more combinations of values directly into the Side Bar. In the example above, notice that the 'Energy source' assumption for one refinery can be changed, and other cost assumptions changed simultaneously. The lack of orange shading on the Side Bar device tells us that the 'Energy source' = "Fuel" assumption is the default. However, the oil price assumption slider is not set to the default value and is therefore shaded orange. If you save this non-default scenario as a Report Page, that Report Page will always open with this mix of default and non-default values- unless you untick the Variable states option under This page will capture: in the Create Page dialog. If you do untick this option, the Report Page will always open with the default values set for all Variables. The user can of course change them at any time.
Note: notice above that all the calculated Formula columns display blue headers in the Table View.
Links:
[1] http://kb.visokio.com/kb/useful-formulae
[2] http://kb.visokio.com/kb/functions-guide
[3] http://kb.visokio.com/formula-editor
[4] http://kb.visokio.com/defining-variables
[5] http://kb.visokio.com/manage-fields
[6] http://kb.visokio.com/node/185
[7] http://kb.visokio.com/kb/subset-functions
[8] http://kb.visokio.com/kb/functions-guide-deprecated
[9] http://kb.visokio.com/kb/js-functions-guide
[10] https://omniscope.me/internal/appsupport/Functions Guide.iok/
[11] http://kb.visokio.com/dates-and-times
[12] http://kb.visokio.com/functions-guide/declare
[13] http://en.wikipedia.org/wiki/Levenshtein_distance
[14] http://www.regular-expressions.info
[15] https://developer.mozilla.org/en/JavaScript/Reference
[16] http://en.wikipedia.org/wiki/Soundex
[17] http://download.oracle.com/javase/tutorial/i18n/format/decimalFormat.html
[18] http://www.w3schools.com/xpath/
[19] http://kb.visokio.com/kb/scripting
[20] http://kb.visokio.com/dates-and-times#dateformats
[21] http://kb.visokio.com/files/Resources/KB/KBFunctionsGuide152/RankingTop10Bottom5.iok
[22] http://kb.visokio.com/files/Resources/KB/KBFunctionsGuide152/RankingDataSubsets.iok
[23] http://kb.visokio.com/files/Resources/KB/KBFunctionsGuide152/PeriodicChangesOverTime.iok
[24] http://kb.visokio.com/kb/subset-functions-2-5
[25] http://kb.visokio.com/functions-guide#SUBSET
[26] http://kb.visokio.com/functions-guide#INTERSECTION
[27] http://kb.visokio.com/functions-guide#UNION
[28] http://kb.visokio.com/functions-guide#INVERSE
[29] http://kb.visokio.com/functions-guide#SUBSET_MEAN
[30] http://kb.visokio.com/functions-guide#SUBSET_SUM
[31] http://kb.visokio.com/functions-guide#RANK
[32] http://kb.visokio.com/functions-guide#RECORDCOUNT
[33] http://kb.visokio.com/functions-guide#SUBSET2
[34] http://kb.visokio.com/functions-guide#SUBSET3
[35] http://appsupport.visokio.com/appsupport/symbolPrices.cfm
[36] http://appsupport.visokio.com/appsupport/yahooFinanceTodaysPrice.cfm
[37] http://appsupport.visokio.com/appsupport/yahooFinanceYearPrice.cfm
[38] http://kb.visokio.com/functions-guide
[39] http://kb.visokio.com/formula-fields
[40] http://kb.visokio.com/formula-editor-functions-list
[41] http://kb.visokio.com/node/152
[42] http://forums.visokio.com/categories/ideas